Key Takeaways
- Instead of hardcoded rules and static schemas, agents can use vector similarity to query each other’s knowledge—turning isolated automations into dynamic collaborators.
- Using different embedding versions across agents creates semantic misalignment and unpredictable results. Standardize the model pipeline across your entire agent ecosystem.
- Shared vector stores, query auditing, semantic routers, and permission boundaries are essential for secure, maintainable inter-agent communication.
- Vague queries, semantic drift, and latency stacking can quietly degrade performance. Logging and tuning retrieval quality should be part of your ongoing operations.
- Embedding-powered agents break down knowledge silos—transforming stale documentation into living, retrievable context. But it only works if the enterprise treats this as a system design problem, not a tech experiment.
If you’ve worked with multi-agent systems in enterprise environments, you already know the Achilles’ heel: siloed knowledge. Each agent might excel in a narrowly defined task—whether that’s answering HR queries, fetching financial metrics, or surfacing SOPs—but the moment you expect them to share knowledge contextually, things get muddy.
APIs and pre-baked intents only go so far. If one agent knows something, how exactly should another discover, interpret, and apply it without drowning in complexity or hardcoded logic? The answer, increasingly, lies in embeddings.
Vector-based representations—embeddings—are quietly reshaping how autonomous agents exchange meaning, not just data. But as with most things that sound elegant in theory, the real value lies in the gritty application.
Also read: Applying the A2A Protocol in Multi-Agent Business Environments
Why Traditional Agent Communication Falls Apart
We’ve built service bots, virtual assistants, and microservice orchestrators for years. So why is knowledge sharing across agents still so brittle?
Because traditional agent communication depends on:
- Explicit schemas: Agent A must know exactly how Agent B structures information.
- Static intents: Sharing only works if the interaction was pre-planned.
- APIs without semantics: JSON payloads lack shared understanding.
So if your Finance Assistant bot knows the quarterly forecast logic and the Strategy Agent is trying to compile a business outlook, you end up writing brittle glue code: “fetch this, if that, then pipe it here.” It’s fine at prototype scale. It collapses in production.What if agents didn’t need shared intent schemas? What if they could infer meaning from each other’s knowledge bases? That’s where embeddings come in.
Embeddings: Meaning, Not Format
Embeddings convert text (or any data modality, really) into a multi-dimensional vector. But this isn’t just a trick to make cosine similarity work. It’s a new foundation for semantic understanding—across agents.
When Agent A stores a document as a set of embeddings (say, using OpenAI’s text-embedding-3-small or Cohere’s models), Agent B doesn’t need to know anything about the source format. It just needs to generate its embedding for a query—and then perform a similarity search.
In other words, agents don’t exchange raw data; they exchange meaning in vector space.
This subtle shift opens up radically new architectures.
Real-World Enterprise Use Case: Cross-Department Agent Collaboration
Let’s take a concrete example from a healthcare enterprise we worked with:
- Agent A: Operates in the compliance department, responsible for surfacing policy documents tied to state-specific telehealth regulations.
- Agent B: Lives in the operations team, handling scheduling logic for physicians, including rules about state licensing.
In the past, Agent B had to “ask” Agent A’s team (or API) for static lookup tables or pre-approved rulesets. Tedious, error-prone, and slow to update.
Instead, we embedded all compliance documents into a vector store (via LangChain + FAISS + Azure Blob for document storage). Then, Agent B could vector-search directly using natural language—e.g., “What’s the rule for a Pennsylvania-based doctor seeing an Ohio patient?”
No more API specs. Just semantic retrieval, cross-agent.
So, How Does This Work in a Multi-Agent Setup?
Here’s the architecture that’s increasingly becoming the gold standard:
- Each agent has its vector store (or namespace within a shared store). Think: a private memory space, structured as embeddings.
- Embeddings are generated at ingestion (not retrieval). This reduces latency and avoids inconsistency. Whether using OpenAI, Cohere, or in-house embedding models, precompute.
- Agents query other agents via semantic protocols, not REST APIs. Instead of “GET /compliance-policy?id=1234,” Agent B says, “Retrieve the top 3 results for this semantic query: [embedding vector].”
- Context handoff happens via shared vector references or top-k chunks. The receiving agent doesn’t have to decode logic, only interpret semantic meaning.
This is not abstract theory. It’s being implemented in real enterprise ecosystems. And it works—until it doesn’t.
The Catches No One Tells You About
Using embeddings is powerful. But it’s not magic. Some hard-earned lessons from the trenches:
Semantic drift is real
If two agents use slightly different embedding models (say, different versions or fine-tunes), their vector spaces may not align well. Cosine similarity becomes noisy. Always normalize embedding strategies.
Contextual ambiguity ruins retrieval
Ask a vague question like “What’s the rule here?” and you’ll get poor results. Agents need prompt-engineering heuristics to frame better semantic queries, even when asking each other.
Privacy boundaries can get fuzzy
In regulated domains (finance, healthcare), just because Agent B can semantically query Agent A’s memory doesn’t mean it should. Scoped access and audit logs for inter-agent queries are essential.
Latency stacks up
One agent making 3 sub-agent queries, each involving vector retrieval and reasoning, quickly turns into multi-second delays. Caching and async orchestration help, but aren’t trivial.
Embeddings as Shared Thought, Not Just Memory
Perhaps the most compelling angle is conceptual: embeddings are not just a memory optimization—they are a thinking medium.
- Instead of remembering documents, agents remember ideas.
- Instead of invoking APIs, they collaborate semantically.
- Instead of syncing databases, they align meaning.
This flips the whole knowledge-sharing problem on its head. You no longer ask, “How can I make Agent A understand Agent B’s data?” Instead, you ask, “How can I align their cognitive substrate?”
Embeddings make it possible.
Architecting for Embedded Agent Collaboration:
If you’re planning to build this into your enterprise systems, here are some architectural pointers that go beyond the obvious:
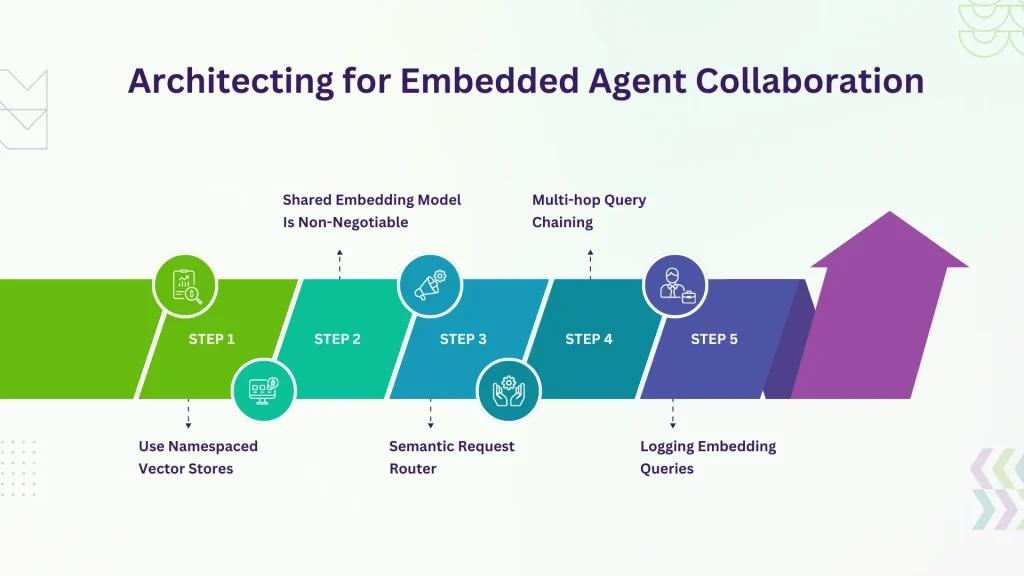
Use Namespaced Vector Stores
Keep each agent’s memory logically segmented. Even if using a single Pinecone or Weaviate instance, use namespaces or indexes per agent. This makes governance, revocation, and debugging much easier.
Shared Embedding Model Is Non-Negotiable
All agents must use the same embedding model—version-locked, ideally via API gateway abstraction. Mismatched embeddings = misaligned cognition.
Semantic Request Router
Introduce a lightweight semantic router: a module that routes queries to agents based on intent and embedding distance, not just API registry. For example, a Procurement Agent asking, “What’s the most recent ESG compliance clause?” gets routed to the Legal Agent.
Multi-hop Query Chaining
Allow agents to recursively query others. E.g., Sales Agent → Contract Agent → Legal Agent. But cap hops to 2 or 3, else you hit latency spirals.
Logging Embedding Queries
Treat embedding-based queries like API calls—log them, monitor similarity scores, analyze miss rates. This helps identify “dumb queries” or retriever failures.
This Isn’t Just a Dev Problem—It’s a Knowledge Architecture Problem
Here’s a thought that doesn’t get enough airtime: this isn’t just about making agents smarter. It’s about rethinking how knowledge lives and flows inside your organization.
Most enterprises still trap knowledge in brittle formats: PDFs, wikis, databases, old SharePoint sites. Even when you automate parts of it, each process becomes an isolated bot or tool.
Embedding-powered agents shift this. They let you:
- Turn legacy docs into live, queryable memory.
- Let teams query without knowing what they’re querying.
- Build real-time intelligence from latent information.
But to get this right, you need buy-in from knowledge managers, data stewards, compliance teams—not just devs.
Embedding Models You Can Use (and When)
Here’s what we’ve seen succeed:
OpenAI text-embedding-3-small or large
Great for enterprise-grade tasks, fast and consistent. Works well with Azure OpenAI deployments.
Cohere embed-v3
Slightly better on long documents; solid multilingual performance.
BGE (BAAI General Embedding)
Popular in open-source circles. Good if you want self-hosted, cost-controlled deployments.
Custom fine-tuned SBERT models
If your domain language is very specific (e.g., pharma, insurance), these can outperform general-purpose models.
Pick one. Stick to it. Embedding misalignment is a silent killer in multi-agent setups.
Final Thoughts
There’s a certain magic in watching two agents “understand” each other—not via brittle APIs or hardcoded rules, but through shared semantics. It feels oddly human, even though it’s vectors down.
We’re entering a phase where enterprises won’t just have bots—they’ll have agent ecosystems. And embedding-powered knowledge sharing is what will make or break those systems.
If you’re still wiring your automations with rigid intent trees and API callouts, maybe it’s time to ask: what if your agents could think together?
That’s not AI hype. That’s just embedding strategy done right.