Key Takeaways
- Agent networks transform credit scoring by integrating diverse, real-time data sources, enabling dynamic, adaptive risk evaluation beyond traditional static models.
- Human oversight remains critical, as autonomous agents can flag anomalies, but nuanced judgment is needed for edge cases, regulatory compliance, and atypical borrowers.
- Continuous learning and adaptation are feasible with AWS ML infrastructure, allowing daily or even minute-level model recalibrations to respond to new market or behavioral data.
- System design matters: effective orchestration, data quality, and feature synchronization are essential; poor implementation can lead to overfitting, conflicting outputs, or fatigue among credit teams.
- Explainability and transparency are not optional: leveraging tools like SHAP or LIME ensures compliance, builds trust, and allows lenders to justify decisions in complex or high-stakes scenarios.
Smart credit scoring isn’t just about upgrading spreadsheets—it’s a big shift from old, one-size-fits-all risk models. What makes it interesting is how agent networks, using AWS Machine Learning, don’t just process more data—they learn, adapt, and sometimes challenge traditional lending rules. Banks and fintechs shouldn’t think of this as pure automation; it’s a mix of advanced statistics and real-world business judgment.
Also read: Smart inventory control via AWS agent networks, optimizing part supplies.
The Data Avalanche: A New Era for Credit Scoring
Many executives like to say, “We’re data-driven now.” But in reality, most credit scoring still relies on a limited set of information—credit histories, payment records, and a few static attributes that feel outdated, like leftovers from the early 2000s. Traditional models work on this small, fixed dataset, which makes them slow to respond to changes and blind to new trends.
Enter agent networks, especially those built with AWS machine learning and related ecosystem tools. These agents can handle far more complex information streams. They pull in documents, API feeds, social media data, business networks, and even real-time behavioral logs. All of this is combined and processed almost immediately, giving a far richer view of an applicant’s creditworthiness.
Human analysts, by contrast, can easily get stuck trying to reconcile these varied data sources. Aligning spreadsheets, PDFs, and databases can take hours—or even days—and errors can creep in along the way. Autonomous agents remove this bottleneck. They collect, check, and merge all the data automatically, highlight inconsistencies, and pass only trustworthy signals forward. This is exactly how agentic systems like those from Akira AI and Mindfields Global operate in practice.
Credit scoring is no longer frozen in last month’s numbers. Decisions can now adapt continuously, reacting to updated company filings, sudden changes in market conditions, or even spikes in social sentiment. In short, agents turn credit scoring from a slow, static process into a dynamic, always-learning system, capable of capturing signals that traditional methods would simply miss.
The Role of Agent Networks
Forget the image of a singular, all-seeing algorithm. Smart credit scoring relies on orchestrated agent networks—a collection of specialized ML agents, each with distinct jobs:
- The Data Collection Agent fetches, cleans, and standardizes everything from credit bureau APIs to scanned NDAs and alternative payment logs.
- A Validation Agent cross-references data for consistency (catching, say, mismatches in address or incorporation dates).
- Financial Metrics Agents compute ratios, profitability measures, and more, sometimes inventing new derived features from raw data.
- Network Analysis Agents map relationships among businesses, flagging systemic risk and counterparty exposure.
- Risk Assessment Agents contextualize each applicant’s standing, blending historic patterns with live market factors.
What’s worth noticing is the emergence of orchestration agents—master minders that coordinate, not dictate, agent behavior. They loosely resemble project managers, assigning tasks, reconciling outcomes, and sometimes handling contradictions (say, when network risk agents down-score a candidate that financial ratio agents flag as benign).
Of course, these agents can—and sometimes do—disagree. That’s not a bug; it’s a feature: automated dissent forces deeper scrutiny, not just rubber-stamped yes/no outcomes.
Adaptation in Action: Learning from New Data
Theory’s great, but field deployment is where opinions sharpen. Recent B2B engagements reveal that adaptation isn’t just periodic retraining—it’s continuous data drift management and, in some cases, surprise recalibrations triggered by external shocks.
For example, a loan processing suite built on AWS SageMaker Data Wrangler and AppSync didn’t just scale to thousands of applications; it updated feature weights daily as the system absorbed fresh payment records, sector-specific stress signals, and even geospatial market shifts. Credit scoring models modulated their risk thresholds not at the whim of quarterly reviews, but daily—or in minutes, if a large client flagged a sudden operational risk.
This level of plasticity is only feasible because AWS ML provides the infrastructure for real-time model retraining, scalable serverless execution (Lambda), and microbatch synchronization. If the idea is that “data tells the story,” then agents built on AWS are constantly re-authoring the plot.
You’ll hear the phrase “real-time risk management” tossed around a lot—sometimes by people who have never had to defend a credit decision to a regulator or an auditor. But in systems architected with AWS’s streaming data tools (Kinesis, S3, DynamoDB), genuine real-time scoring isn’t just possible, it’s defensible. Automated A/B testing and live model performance analytics, via CloudWatch, provide transparency and regulatory assurance—a deep necessity, not a superficial feature.
The Human Factor: Why It Still Matters
Call it cognitive dissonance or pragmatic skepticism, but there’s a persistent human urge to second-guess automation. Experienced lenders know that models, no matter how clever, sometimes miss context—a competitor’s sudden bankruptcy, a regulatory change, or simply the “story behind the data” that credit officers pick up through years of client interactions.
Smart agent networks don’t eliminate this. They augment it, surfacing contradictions, anomalies, and unmodeled risks for human review. In fact:
- Some systems flag borderline decisions for manual underwriting, rather than auto-approve or decline.
- Agents offer explanations, not just predictions—using explainable AI tools like SHAP or LIME to make their logic transparent, a nod to regulatory requirements and human stubbornness.
- Blending human intuition with machine recommendations remains essential. Overly automated systems have tripped up approving high-risk entities that human experts would have flagged instinctively.
A surprising number of credit teams express relief when agents don’t “close the loop” on every case. The room for expert override—the gray zone where nuanced judgment lives—is not going away.
AWS ML: Why the Infrastructure Chose the Design
It’s tempting to conflate AWS-powered smart credit scoring with “just another cloud build.” But field practitioners encounter real, persistent benefits—some expected, others less advertised:
- Data Lake Integration: Centralized repositories (S3/Redshift) allow agents to pull and merge diverse data types, from structured financials to unstructured compliance documents.
- Real-Time Sync: AppSync and Lambda keep models responsive, not lazy, and offer APIs for embedding new signals instantly.
- Managed ML Services: SageMaker and Bedrock deliver not just model deployment but continuous retraining, low-latency inference, and fine-grained versioning.
- Security: AWS’s compliance capabilities (Config, CloudWatch) address regulators’ endless questions about auditability, drift, and fair lending.
- Feature Stores (Feast, SageMaker Feature Store): Handle metadata and feature lineage, vital for debugging unexpected performance drops.
- Streaming Data: Kinesis enables agents to immediately react to transactional signals, market shocks, or fraud alerts without cycling through batch ETL delays.
These aren’t just technical embellishments; they’re prerequisites for credible adaptive scoring in sectors where inaccurate risk ratings can tank a portfolio overnight.
When Agent Networks Fail—And Why
Not every experiment sings. Smart credit scoring can stumble when:
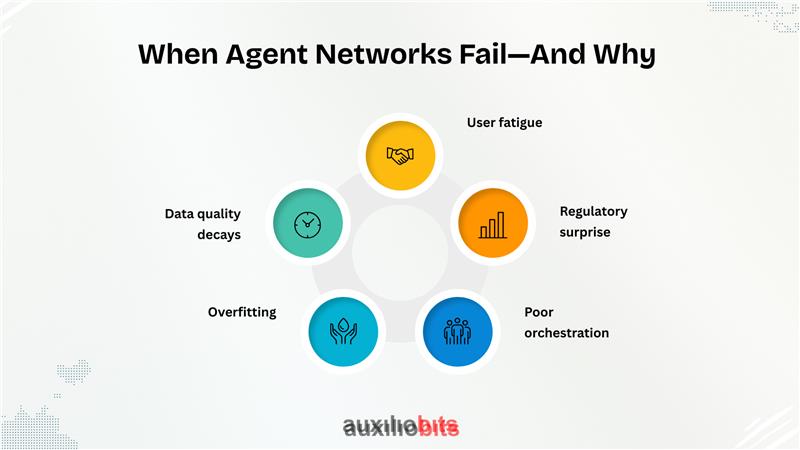
- Data quality decays: No agent is magic—missing, noisy, or biased inputs poison outcomes. Systems might gloss over anomalies that an expert would catch.
- Overfitting: ML agents, tuned too aggressively to recent examples, ignore emergent risk signals. This is a perennial headache, especially post-economic shocks.
- Poor orchestration: Without a strong master agent, sub-agents can compete unproductively—producing conflicting recommendations or, worse, paralyzed indecision.
- Regulatory surprise: Legal frameworks change. Automated models sometimes fail at explainability, a cardinal sin in credit regulation.
- User fatigue: Too many alerts, too much data, and insufficient workflow integration can frustrate credit teams, leading to agent “mute” behaviors or a reversion to manual quoting.
Field-tested agent networks bake in real-time drift detection and self-monitoring, addressing some of these traps. But there’s no silver bullet, just fewer landmines.
Nuances and Subtle Risks
While autonomous agents and real-time scoring bring speed and intelligence to credit decisions, they aren’t flawless. Behind the impressive automation lies a web of subtle challenges that can impact accuracy, fairness, and reliability. Sudden anomalies in data, gaps in explainability, borrowers who don’t fit typical patterns, and poorly tailored agent designs can all create unexpected risks. In this section, we explore these nuances and why careful oversight remains essential, even in highly automated credit environments.
- Real-time scoring isn’t infallible. Sudden data spikes from a security breach or fraudulent actors gaming scoring signals can trip up even the best models.
- Explainability isn’t a regulatory “nice to have.” It’s a core business asset. Lenders who can explain why agents flagged specific risks win trust and avoid penalties.
- Not every borrower fits the ML mold. Agent networks can be blind to atypical—but creditworthy—entities that fall outside their trained distribution.
- Customization is hard. Overly generic agent architectures perform poorly outside their design sector. Financial services, payments, and trade finance all demand tailored agents.
- Data synchronization is mission-critical. Inconsistent, out-of-date features undermine scoring accuracy, especially for rapid loan approvals.
The Road Ahead
Is agentic, ML-powered credit scoring mature enough to replace traditional approaches entirely? That’s the ongoing debate. On the one hand, enterprises deploying adaptive agent networks on AWS routinely report sharper, faster, and more defensible decisions—often at lower operational cost. But at the same time, edge cases, regulatory demands, and the ever-changing nature of business risk keep human experts central to the process.
Credit scoring in the age of AWS-driven agent networks is a finish line—it’s an evolving ecosystem. Sometimes, contradictions appear; sometimes, human intuition overrides the automated score. That isn’t a deficiency; it’s precisely what keeps adaptive, agentic networks credible.