Key Takeaways
- DeepStream powers real-time perception for vision-heavy agents, handling multi-camera feeds and edge deployments efficiently.
- TAO allows enterprises to fine-tune pretrained models for domain-specific tasks while optimizing them for production environments.
- Merlin enables agents to rank and recommend actions intelligently, turning large datasets into actionable insights.
- Combining DeepStream, TAO, and Merlin creates a practical end-to-end workflow for smart agents, from perception to decision-making.
- Successful deployment relies on proper integration, robust data pipelines, and compatible NVIDIA hardware.
If you’ve spent time in enterprise AI over the past five years, NVIDIA’s name has been unavoidable. What began with CUDA and GPU acceleration for research has morphed into an entire stack of domain-specific frameworks: DeepStream for video analytics, TAO (Train, Adapt, Optimize) for model customization, and Merlin for recommender systems. Each claims to accelerate development, but they live in very different parts of the AI landscape.
The question that more and more teams are facing is how these frameworks fit when you’re building “smart agents” that need to see, decide, and interact in real-time environments.
DeepStream: Streaming Eyes for Agents
DeepStream is NVIDIA’s SDK for real-time video analytics. It’s the one you encounter when your agents need to “see” the world: CCTV feeds in a warehouse, traffic cameras at intersections, or thermal imagery in a factory.
The strength of DeepStream is that it isn’t a monolithic product. It’s built on GStreamer, which means you can chain together elements like decode, inference, tracking, and rendering in pipelines. At first, this feels cumbersome, but once you’ve been through a deployment, you realize the advantage: you can swap pieces in and out depending on your use case.
Where it excels in smart agent use cases:
- Detecting events in video feeds, then handing decisions to downstream agents. A robotic arm doesn’t need to watch 100% of frames—just the moment an object crosses a threshold.
- Edge deployments where bandwidth is scarce. Instead of shipping raw video, you stream only the detections (e.g., “object ID 34 crossed line at timestamp”).
- Multi-camera coordination. Logistics firms often need to stitch insights from 20+ cameras without drowning their networks; DeepStream handles batching and multiplexing far better than trying to hack it together with raw PyTorch.
But DeepStream is not a silver bullet. It has limitations that frustrate first-timers:
- Customization is harder than you expect. GStreamer plugins aren’t trivial to write if you want something unusual.
- You end up tied to NVIDIA GPUs (Jetson on edge, Tesla in data center). In practice, this is less a problem than a budgetary question.
- Models need to be pruned or quantized to run efficiently. Deploying a vanilla transformer on video streams will choke
A real example: a retail chain piloted DeepStream to monitor shelf stock. It worked beautifully in the lab but crumbled when deployed across stores with varied lighting, camera placements, and network conditions. They salvaged the project by running lightweight detection at the edge and pushing only metadata to central servers. DeepStream gave them the backbone, but the real engineering was in the adaptation.
TAO: The Middle Ground Between Research and Production
TAO Toolkit (Train, Adapt, Optimize) is NVIDIA’s answer to the common pain point: enterprises don’t want to train models from scratch, but they can’t deploy off-the-shelf ones either.
With TAO, you start from pretrained NVIDIA models—vision, speech, and NLP—and adapt them with your data. The “optimize” part is what makes it valuable for smart agents: pruning, quantization, and TensorRT export are built in. That means your adapted model isn’t just accurate but also deployable on Jetsons, GPUs in the cloud, or even embedded devices.
What makes TAO interesting is how it plays in the messy middle:
- Research teams love experimenting with Hugging Face models or custom architectures.
- Production teams just want a working binary that fits into a container.
- TAO bridges these camps by giving guardrails—enough flexibility for data adaptation, but not so much rope that you hang yourself with hyperparameter rabbit holes.
In the context of agents:
- A warehouse robot agent using DeepStream for object detection might rely on TAO to fine-tune a detection model for “boxes with damaged corners” (something COCO never taught it).
- Voice-based agents in customer service could take NVIDIA speech models via TAO, fine-tune them with local accents, and then export them to an optimized inference engine.
- TAO helps standardize models so that your inference servers aren’t dealing with a zoo of formats.
The catch: TAO works best if you accept NVIDIA’s ecosystem. Try exporting a TAO model to non-NVIDIA hardware, and the experience gets rocky. Also, while the low-code interface (CLI and Jupyter workflows) is helpful for quick starts, advanced practitioners often find it restrictive—they want to modify the guts, and TAO doesn’t really allow that.
Still, for most enterprise teams who are drowning in proof-of-concepts but starving for production-ready models, TAO is pragmatic. It’s opinionated in the right ways.
Merlin: Teaching Agents to Recommend, Not Just React
If DeepStream gives your agents eyes and TAO gives them tuned brains, Merlin is the framework that teaches them taste—or more precisely, preference modeling. It’s NVIDIA’s end-to-end recommender system library, optimized for GPUs.
Recommenders aren’t only for e-commerce. In agent use cases, they appear in subtle places:
- A procurement agent decides which suppliers to suggest to a buyer.
- A digital health agent prioritizes which alerts a clinician should see first.
- A customer support bot ranking next-best actions instead of spitting out static scripts.
Merlin covers the stack from feature engineering (NVTabular) to model training (HugeCTR, Transformers4Rec) to deployment. And unlike TAO, it leans into scale—handling terabyte-scale tabular data with GPU acceleration.
What makes Merlin attractive for agentic systems is that it doesn’t just predict a label; it ranks possibilities. That’s closer to how human agents behave—rarely giving a single binary decision, more often suggesting, “Here are three good options.”
Challenges with Merlin in practice:
- Integration with non-tabular data is still clunky. Agents that need to combine video, text, and structured logs require extra glue code.
- It assumes a level of MLOps maturity. Without feature stores, data versioning, and retraining pipelines, Merlin becomes brittle.
- The performance gains are stunning in benchmark settings, but real-world deployments often bottleneck on data ingestion rather than model computation.
One fintech pilot illustrates this: they used Merlin to recommend the “next best compliance action” for analysts reviewing suspicious transactions. The models were solid, but the real delay came from fetching and joining disparate datasets. Merlin didn’t solve that. It sped up the ranking, but the pipeline around it had to be rebuilt.
How They Fit Together in Agent Architectures
The most useful way to compare DeepStream, TAO, and Merlin is not side-by-side features but in workflow sequence. Think of an agent pipeline:
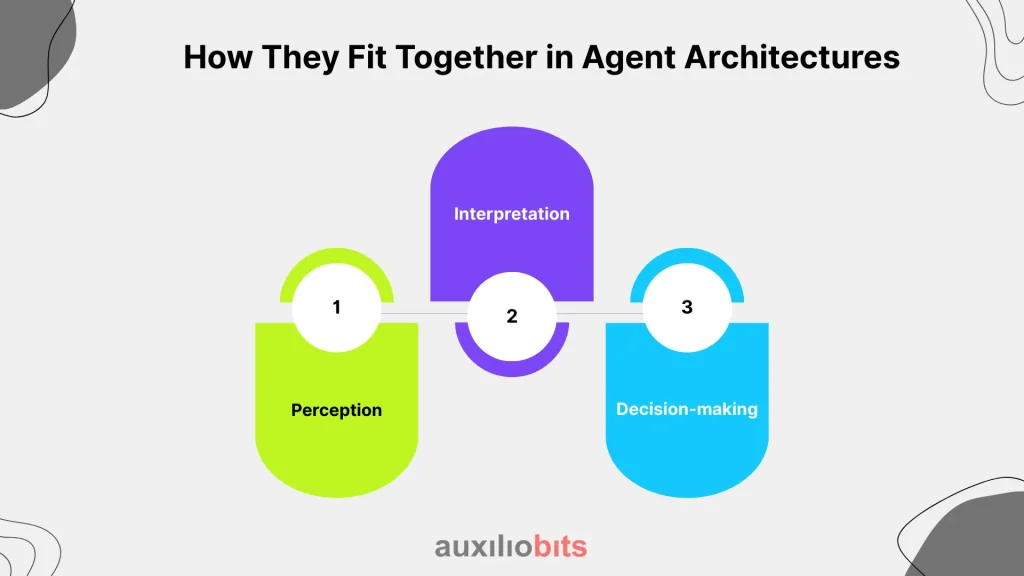
1. Perception: ingest sensory input (video, speech, logs).
- DeepStream dominates here. It handles decoding, batching, inference, and event extraction in real time.
2. Interpretation: refine or adapt models to domain-specific nuances.
- TAO slots in here. Fine-tune detection, speech, or NLP models with your proprietary data.
3. Decision-making: rank or recommend possible action
- Merlin excels here. Agents aren’t just recognizing patterns; they’re prioritizing outcomes.
This triad doesn’t cover everything—control policies, memory, and orchestration layers are missing—but it reflects a practical stack many enterprises are already experimenting with.
Comparative Observations
Some distinctions matter less on paper than they do in the field. A few stand out:
Ease of adoption:
- DeepStream feels intimidating at first, but once you learn GStreamer mental models, scaling to dozens of streams is straightforward.
- TAO lowers the barrier for fine-tuning, but advanced customization is boxed in.
- Merlin requires a serious data engineering backbone; without that, you’ll blame the tool for what is really a pipeline problem.
- Hardware lock-in: all three are NVIDIA-centric. You can wrangle portability, but the friction usually outweighs the savings.
- Agent context fit:
- Vision-heavy agents → DeepStream is almost unavoidable.
- Agents needing customized but lightweight models → TAO.
- Agents navigating choice architectures (recommenders, policy suggestions) → Merlin.
- Enterprise reality check: Proof-of-concept demos often hide the cost of integration. Engineers spend more hours on data labeling, feature pipelines, and deployment quirks than on model training. These frameworks help, but they don’t erase that grind.
Where are the gaps?
None of these frameworks yet solves the orchestration problem. Smart agents aren’t just “perception + model + recommendation.” They need memory, multi-modal reasoning, and a governance layer to ensure decisions are auditable.
Right now, engineers glue DeepStream events into Kafka topics, feed TAO-adapted models into Triton Inference Server, and push Merlin recommendations into APIs. That works, but it’s brittle..
The opportunity is for NVIDIA—or frankly, an ecosystem partner—to connect these dots into a cohesive agent platform. Until then, enterprises will keep stitching pieces together with custom middleware.
Final Thoughts
Comparisons only get you so far. In practice, teams choose based on constraints:
- Do you already have Jetsons in the field? Then DeepStream is almost inevitable.
- Do you lack ML researchers but still need domain-tuned models? TAO will save you.
- Do you have mountains of behavioral or tabular data and GPUs to spare? Merlin pays off.
All three succeed—and fail spectacularly when dropped into the wrong context. The frameworks are powerful, but they are not turnkey agent platforms. They’re building blocks. And like any building blocks, their value depends less on their polish than on the hands arranging them.