Key Takeaways
- Fine-tuning is not a shortcut—it’s a precision tool best used for stable, high-value, and well-understood processes.
- Data quality trumps quantity. Clean, well-annotated, nuanced examples make all the difference.
- Smaller models can win. Don’t default to the biggest model—match the model size to the task and constraints.
- Process understanding matters. Fine-tuning without knowing how your process works is a waste of time and computing.
- Hybrid approaches usually win. Fine-tuning + prompt engineering + retrieval = the real enterprise stack.
When enterprises first started experimenting with GPT-based systems, the results were… underwhelming. Sure, the base models could write a decent FAQ or answer common helpdesk queries, but ask them to take action—real, contextual action—inside a process like invoice approval or claims adjudication, and they’d fall flat.
Why? Because general-purpose models aren’t good at processing nuance. They’ve read every Wikipedia article, scraped countless forums, and been trained on a deluge of internet text—but they haven’t sat in on your procurement meetings or watched your finance team navigate five legacy systems just to close the books.
To make GPT genuinely useful for business process automation, fine-tuning is often essential. But—and this is crucial—it’s not a silver bullet. Fine-tuning can enhance specificity, yes, but it also introduces fragility if done naively. So how do we do it right?
Also read: Forecasting Variance Analysis with GPT-4o and LangGraph: A New Era of Conversational Forecasting
The Myth of the All-Knowing Model
Before we talk about how to fine-tune, we need to be honest about why. There’s a myth in some enterprise circles that GPT “already knows everything.” This is partially true in the same way that a junior analyst “knows Excel” on day one: they’ve seen the tools, but they don’t know how your team uses them.
Take the example of an insurance company trying to automate first notice of loss (FNOL) processing. A base GPT-4 model can probably define “FNOL” if asked. But it won’t know:
- The exact triage logic used internally
- Which data fields are non-negotiable for regulatory reasons
- How exceptions like incomplete VINs should be handled
These are the kinds of decisions embedded in tacit knowledge, institutional memory, and fragmented SOPs. No amount of pretraining can compensate for that. Fine-tuning helps you bridge the gap.
Fine-Tuning: What It Means in Practice
Let’s disambiguate a bit. In common usage, “fine-tuning” often gets thrown around to mean a bunch of different things:
- Updating a model’s weights with new data (true fine-tuning)
- Using retrieval-augmented generation (RAG) to inject local context
- Prompt engineering with few-shot examples
- Instruction tuning or SFT (Supervised Fine-Tuning) with curated dialogue datasets
What most enterprises think they need is full-blown fine-tuning. What they usually need is a hybrid approach—structured prompt templates augmented with domain-specific memory and perhaps some light fine-tuning at the edge. But sometimes, true fine-tuning is warranted. Here’s when.
When Fine-Tuning Makes Sense (and When It Doesn’t)
Fine-tuning a model is expensive—not just in compute, but in effort. And unless your process has stable logic and a clear taxonomy of outcomes, you’re likely to make things worse, not better. That said, here are a few situations where it can be transformative:
Good candidates for fine-tuning:
- Stable, high-volume processes like invoice categorization, where the input-output structure is consistent
- Jargon-heavy verticals like pharma or aerospace manufacturing
- Processes requiring task-specific reasoning, such as tax classification or eligibility checks, where the base model’s logic falls short
Bad candidates:
- Highly variable tasks like executive writing or unstructured brainstorming
- Situations where regulations or business rules change often
- Low-data environments—especially if the team lacks clean, annotated examples
As a rule of thumb: if humans follow a standard playbook, a fine-tuned model can probably do it too. But if your team spends more time interpreting edge cases than following SOPs, you may want to stick with more dynamic RAG-based designs.
Real-World Case: Claims Adjudication for a Regional Health Insurer
A midsize health insurer was looking to reduce human effort in claims adjudication. Their workflow was complex but repeatable: extract key fields from a claim, apply benefit rules, and determine payout eligibility.
They had tried using GPT with structured prompts and got decent results—but there were constant misses. The model confused similar-sounding CPT codes, couldn’t distinguish between primary and secondary diagnoses, and made assumptions that weren’t legally defensible.
We worked with them to fine-tune a smaller GPT-3.5 model on 40,000 labeled claim samples, incorporating specific annotations like:
- Which fields were mandatory vs. optional
- Which codes should trigger manual review?
- How to handle conflicting data
The result? Accuracy jumped from ~76% to 92%, and manual intervention dropped by half. But here’s the kicker: had they skipped the annotation phase and just fine-tuned on raw input/output pairs, they likely would’ve made things worse. The model would have learned biases, not rules.
The Data Isn’t Optional—It Is the Product
Here’s a point that often gets glossed over: the success of fine-tuning hinges almost entirely on your data. If the data is inconsistent, contradictory, or unrepresentative of edge cases, no amount of model magic will save you.
Some rules we follow before even considering fine-tuning:
- Annotate with intent in mind. Don’t just label outputs—label the reasoning.
- Normalize formatting across records. GPTs are surprisingly sensitive to trivial inconsistencies.
- Include hard negatives—examples that are close to correct but subtly wrong.
- Map inputs to process steps, not just outputs. A model that can explain why it did something is easier to trust and debug.
And one subtle but important tactic: when labeling, have multiple annotators disagree and then reconcile. That reconciliation process surfaces nuance that the model can learn from.
What You Fine-Tune On Also Matters?
Not all models are created equal. Fine-tuning GPT-2? Waste of time. GPT-3.5? Viable. GPT-4? Possible, though at the time of writing, OpenAI has not yet enabled broad fine-tuning access for GPT-4.
Other options:
- Open-source models like LLaMA 3, Mistral, or Mixtral are increasingly viable. Hugging Face’s ecosystem makes this easy, but be ready for infrastructure work.
- Smaller distilled models like Phi-3 or TinyLLaMA can be fine-tuned efficiently and embedded directly into edge workflows.
Use smaller models where latency or privacy matters. Save the big guns for tasks requiring generalization across large input spaces.
Fine-Tuning ≠ Forgetting: The Importance of Prompt Alignment
A mistake we see often: after fine-tuning, teams abandon prompt engineering entirely. Don’t. You still need good prompt scaffolding to get reliable results.
In fact, post-fine-tuning, your prompts may need to remind the model of the process context—especially if your fine-tuning dataset had variability in how instructions were phrased.
Consider prompts that:
- Anchor the model with a “system message” describing the process logic
- Provide structured input (e.g., form fields or JSON)
- Ask the model to explain its reasoning before giving the final answer (a trick that improves reliability in edge cases)
You’re not just creating a model—you’re building a collaboration between it and your workflow. Don’t neglect the interface.
Failure Modes and Fixes
No deployment goes perfectly. Here are common pitfalls and how to mitigate them:
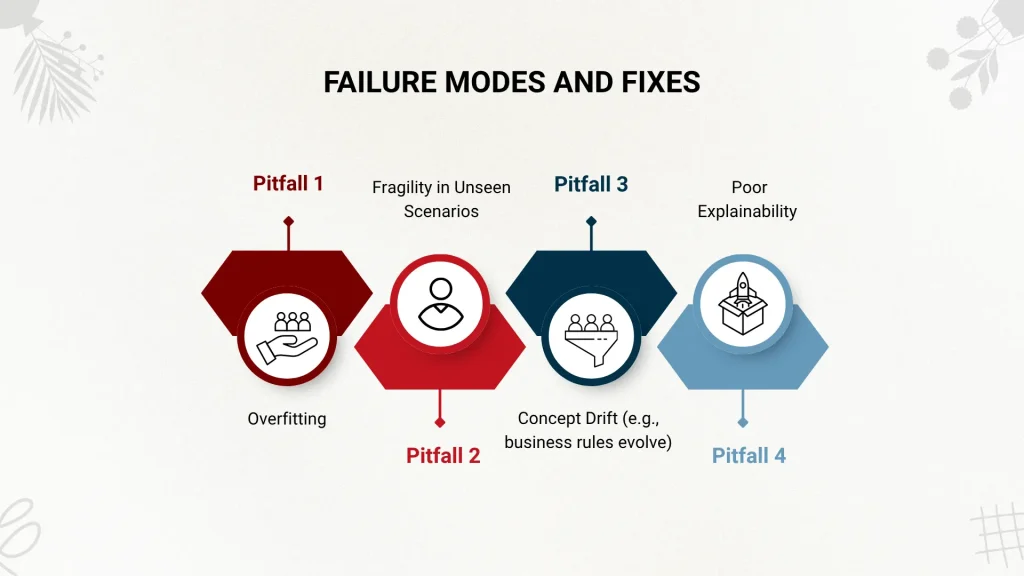
- Pitfall 1: Overfitting
Fix: Use validation datasets that include newer or slightly off-pattern inputs. Introduce random perturbations during training.
- Pitfall 2: Fragility in Unseen Scenarios
Fix: Include synthetic examples of rare cases, or fallback to a retrieval-based design for long-tail queries.
- Pitfall 3: Concept Drift (e.g., business rules evolve)
Fix: Combine fine-tuning with dynamic memory layers or retrain periodically. Use a logging system to track model behavior drift over time.
- Pitfall 4: Poor Explainability
Fix: During fine-tuning, train the model to explain before it answers. This has surprisingly large benefits for both reliability and trust.
And Finally: Know When to Walk Away
Not every use case needs a custom mod. Many don’t. Sometimes your best bet is RAG plus a rules engine. Sometimes a simpler classification model with a structured frontend outperforms a fancy language model.
But when you’re automating real business processes—those messy, multi-system, exception-ridden pipelines that people quietly dread—fine-tuning can be the differentiator that turns a prototype into production.
Just don’t expect miracles. Expect work. If you’re serious about using GPT in your core workflows—not just for chatbots or boilerplate generation—start by studying your process, not your model. The machine can learn, but it needs a teacher who understands the work.
And sometimes, that teacher is a line manager with a spreadsheet, not a data scientist with a GPU.