Key Takeaways
- RAG ensures financial institutions access the latest regulatory documents, helping them respond accurately to evolving compliance standards like AML, KYC, and GDPR.
- By grounding responses in real documents, RAG significantly minimizes the risk of hallucinations, making AI-generated compliance answers more trustworthy and factual.
- Using domain-specific embeddings and metadata tagging enhances the system’s ability to retrieve the most relevant, context-aware sections from complex financial texts.
- RAG provides clear traceability by citing document sources, enabling compliance teams to justify decisions during audits and maintain regulatory confidence.
- RAG seamlessly integrates search and generation, offering a scalable approach to automating and supporting financial compliance workflows with high reliability.
Regardless of the industry, it is mandatory always to follow the set guidelines. This also has implications for the financial sector. However, they struggle a lot while doing so. Now and then, new rules are invented. Additionally, existing rules change in the blink of an eye. If financial settings fail to stay up to date, they either face significant fines or damage their reputation. Hence, compliance is of utmost importance. With the rise of artificial intelligence, financial institutions can now utilize tools to help them keep up conveniently.
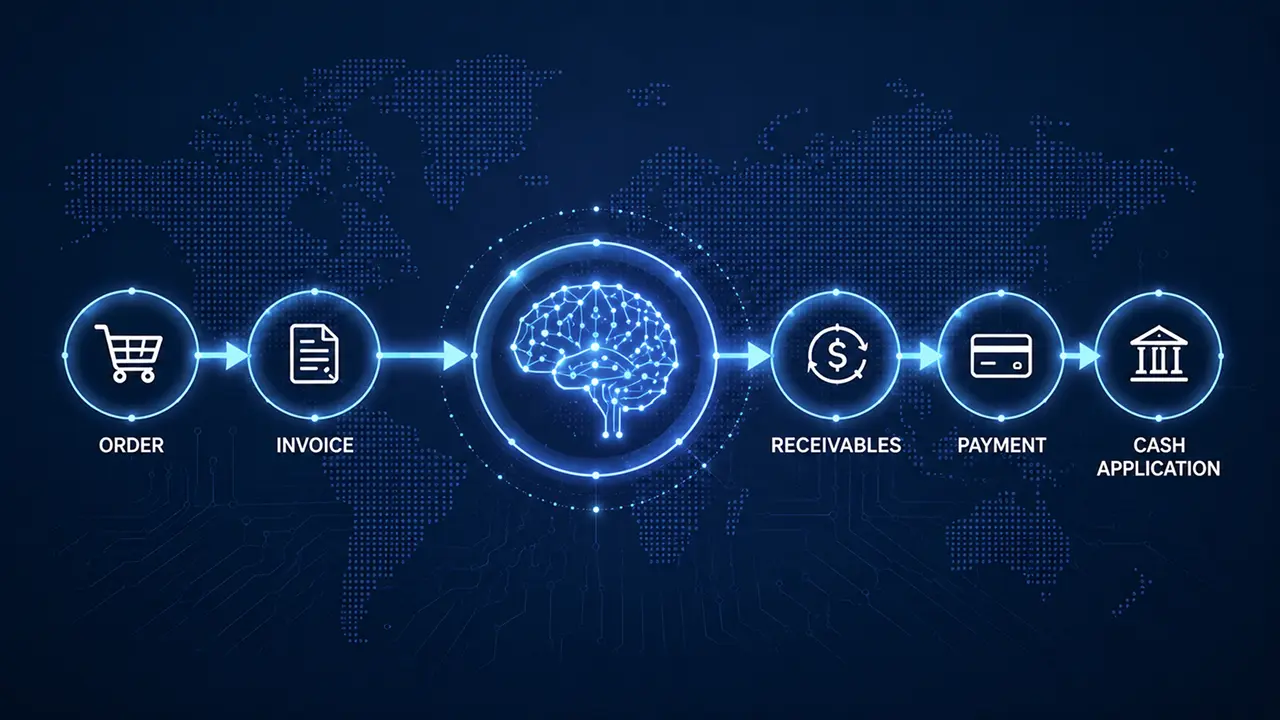
One of the most beneficial tools is retrieval augmented generation, or RAG. It functions by utilizing technologies like generative AI and search engines. An RAG system retrieves relevant details instead of answering a customer query straightaway. However, this information is collected from a reliable source only. Once the data is collected, generative AI will summarize that information and respond to the customer.
This makes RAG especially useful for domain-specific knowledge, like financial compliance. Regulations can be complex and very specific to certain industries or countries. A regular AI model might not have up-to-date or detailed enough information. However, with RAG, the system always looks at the latest documents and rules before generating a response.
For example, if a compliance officer asks, “What are the reporting rules under the latest SEC guideline?”, a RAG system will search the latest SEC documents, retrieve the most relevant section, and then generate an answer in plain language. This saves time and reduces the chances of missing important updates.
Large Language Models like GPT, BERT, or similar AI tools are trained on vast amounts of data from the internet. While powerful, they have a significant limitation: they can only answer questions based on the data they were trained on. This means they might miss recent changes, lack access to private company information, or even make up answers (a problem known as “hallucination”).That’s where RAG architecture helps.
Traditional LLM vs. RAG
Let’s compare a traditional LLM with RAG.
Traditional LLM: When you ask a question, the model tries to answer it using only the knowledge stored during training. If your question is highly specific or recent, for example, “What are the 2024 tax rules for cryptocurrency reporting?”—the model might not have the correct answer or may generate one that sounds right but isn’t true.
RAG Architecture: This approach adds a retrieval step before the model generates an answer. Here’s how it works:
1. Retrieve
The system first uses a search tool (like a keyword-based search or a vector database) to find the most relevant documents from a trusted knowledge base. This could include PDFs, legal documents, compliance manuals, audit logs, or financial regulations.
2. Augment
The retrieved documents are combined with your original question and passed as context to the language model. This gives the AI fresh, relevant, and grounded information.
3. Generate
The model uses this real-time context to generate an answer, making the response more accurate, specific, and trustworthy.
Imagine asking a lawyer a question.
- A traditional LLM is like a lawyer who answers from memory.
- A RAG system is like a lawyer who walks into a law library, finds the latest rulebook, reads the relevant section, and then gives you an answer.
This approach dramatically improves reliability, especially in industries like finance, where up-to-date and accurate information is critical.
Why RAG is a Game-Changer for Financial Compliance?
The financial industry operates in one of the most heavily regulated environments in the world. Whether preventing money laundering, verifying customer identities, or ensuring data privacy, firms must comply with various constantly changing legal requirements. This is where Retrieval-Augmented Generation (RAG) becomes a powerful tool. It brings a more innovative, more reliable approach to navigating complex compliance challenges. Let’s explore how RAG addresses four of the most significant issues in financial compliance.
1. Constantly Changing Regulations
Financial compliance involves keeping up with a wide range of evolving rules and standards, such as AML (Anti-Money Laundering), KYC (Know Your Customer), GDPR (data protection), and global banking standards like Basel III. These regulations are updated frequently, often with subtle but critical changes. Traditional AI models, trained once and static thereafter, quickly become outdated.
RAG solves this by retrieving information from live, up-to-date data sources. Instead of relying on what the model “remembers” from training, RAG-enabled systems query a connected database of the latest legal documents, regulatory guidelines, or company policies in real time. This ensures the AI’s answers reflect current rules, helping compliance teams stay one step ahead.
2. Highly Specific and Technical Language
Regulatory documents contain formal, legal, and technical language that can be difficult for a general-purpose AI model to understand. Financial compliance often hinges on interpreting small nuances in these texts. For example, a single clause in a policy may change how a firm handles a transaction.
RAG can be fine-tuned with domain-specific configurations, meaning it can be set up to understand financial regulations’ vocabulary, tone, and structure. It can extract and surface only the most relevant, context-aware sections of complex legal text when combined with retrieval from appropriate documents. This makes it easier for compliance professionals to quickly get accurate answers without digging through long documents.
3. Auditability and Traceability
In regulated industries, being compliant is not enough—you must also be able to prove it. That means showing auditors and regulators how decisions were made, what data was consulted, and where policies were followed.
Every AI-generated answer can be traced back to the source document with RAG. When the model explains, it can also cite the exact section of the regulation or policy that supports the answer. This level of transparency gives compliance teams confidence in the system and provides a clear audit trail for every interaction.
4. Reduced Hallucination
One significant concern with generative AI is “hallucination,” where the model fabricates information that sounds correct but isn’t based on any real source. In industries like finance, where accuracy is critical, this is unacceptable.
RAG dramatically reduces hallucinations by grounding the model’s response in real, retrieved documents. Instead of guessing, the model builds its response based on facts from trusted sources. This makes the output far more reliable, particularly when handling sensitive or high-stakes compliance queries.
Core Components of a RAG System for Financial Compliance
Let’s look at what makes up a RAG system tailored to financial compliance:
1. Knowledge Base (Document Store)
This contains all your compliance documents:
- Regulatory filings (SEC, FINRA, etc.)
- Internal policies
- Risk and audit reports
- Legal contracts
- Training manuals
These documents are usually stored in a vector database like Pinecone, Weaviate, or Azure Cognitive Search after being chunked and embedded (converted into machine-understandable formats).
2. Retriever (Search Engine)
This component finds the most relevant text from the knowledge base. It uses techniques like semantic search to understand meaning, not just keywords.
Popular tools:
- FAISS (Facebook AI Similarity Search)
- Elasticsearch with dense retrieval
- Azure AI Search with vector capabilities
3. Generator (LLM)
This is the brain that answers the question. It takes your query plus the retrieved documents and generates a precise, human-readable answer.
Models can be
- OpenAI GPT-4
- Azure OpenAI Service (good for enterprise)
- LlamaIndex + LangChain-based generators
4. Orchestration Layer
This connects all the pieces—managing how documents are indexed, queries are processed, and outputs are formatted.
Popular tools:
- LangChain
- Semantic Kernel (Microsoft)
- RAGAS (for evaluation)
Building a RAG System for Financial Compliance: Best Practices
Creating a Retrieval-Augmented Generation (RAG) system for financial compliance isn’t just about connecting a chatbot to a search engine. Careful design and tuning are essential to making it reliable and helpful in a high-stakes environment like finance. Below are some best practices to ensure your RAG system delivers accurate, compliant, and trustworthy responses.
1. Use Domain-Specific Embeddings
Generic language models and embeddings often fail to grasp the nuances of financial or legal terminology. Use domain-specific embeddings trained on financial texts, such as FinBERT or fine-tuned versions of OpenAI or Azure models tailored for finance, to improve understanding and retrieval accuracy. These embeddings better capture the meaning of complex regulations, legal clauses, and policy jargon.
2. Regularly Update Your Knowledge Base
Regulations change frequently. Your RAG system should always access the most up-to-date documents. Set up scheduled crawlers or ETL pipelines to pull new documents from trusted sources (e.g., government portals, financial authorities, internal repositories) and refresh your vector store regularly.
3. Chunk Documents Wisely
Avoid breaking text arbitrarily when splitting documents into pieces (for embedding and retrieval). Instead, divide it into logical sections, such as headings, bullet points, or paragraph breaks. This ensures each chunk maintains practical context, improving the relevance of search results and generated responses.
4. Add Metadata
Tag each document and chunk with metadata like regulation name, jurisdiction, date, source, and document type. This allows your retriever to filter and rank documents more precisely, especially in multi-jurisdictional or industry-specific compliance environments.
5. Evaluate Output
Use evaluation tools like RAGAS to test how accurate, relevant, and grounded your outputs are. Include human-in-the-loop reviews for high-risk queries to ensure reliability and build trust in the system.
Conclusion
RAG architecture is a powerful way to combine search and generative AI strengths. For financial compliance, where accuracy, traceability, and domain expertise are critical, it provides a scalable solution to navigating the ever-growing body of regulations.
As the financial sector becomes more complex, tools like RAG offer a way to stay compliant, reduce manual work, and make better decisions — all while grounding outputs in real, verifiable data.