
Key Takeaways
- Agent “versions” must capture behavior, not just code. Traditional versioning collapses in agent ecosystems because behavior is shaped by prompts, models, hyperparameters, tools, embeddings, and memory. If you can’t reproduce the behavior, you don’t have a real version.
- Rollbacks are hard because agents accumulate state—and that state ages. Memory, embeddings, cached context, and tool outputs all shift over time. Rolling back code without rolling back context creates inconsistent, unpredictable behavior.
- A four-layer versioning taxonomy prevents chaos. Tracking the cognitive layer, model layer, knowledge context, and tool contracts separately brings clarity to what changed—and what needs to be restored during rollback.
- Shadow-mode testing is the closest thing to safety in agent releases. Running new agent versions in parallel and measuring behavioral divergence is the only reliable way to catch regressions before they hit production.
- Some agents should never be rolled back. Agents with long-term memory tied to business events, legal decisions, or chained downstream transactions should be “rolled forward,” not reverted, to avoid corrupting state or duplicating actions.
Enterprises rarely talk about versioning until something breaks. Odd, considering how much energy goes into monitoring uptime, handling secret rotation, or keeping CI/CD pipelines “green.” But when it comes to autonomous or semi-autonomous agents—LLM-powered workers, rule-based micro-agents, or hybrid systems—versioning becomes an existential requirement. You’re not simply updating code; you’re modifying behavior.
And behavior, unlike code, tends to wander.
Many teams new to agent deployments assume they can treat them like any other microservice: tag the release, push through staging, deploy to prod, and move on. They discover quickly that the assumptions baked into traditional software delivery break down in odd ways. Agents learn (or appear to). They depend heavily on context. They occasionally behave differently with the same inputs. They pick up environmental signals developers never intended them to. Small shifts in model configuration—temperature, context size, memory strategies—can surface as large shifts in outcome consistency.
This is why versioning and rollbacks in agent ecosystems require more intention than most architectures currently accommodate.
Also read: Deploying Swarm Agents for Exploratory Business Research
Why Agent Versioning Is a Different Beast
You can tag a Docker image and call it a version. Easy. But how do you version something whose behavior depends on:
- An LLM that itself evolves upstream every few weeks
- A retrieval layer whose embedding store changes with every incremental update
- A tool-invocation policy that modifies behavior based on real-time feedback
- External APIs that may subtly shift responses
- A memory subsystem that grows with interaction history
For example, a team learned this the hard way. They upgraded from GPT-4.1 to GPT-4.1-Turbo for an internal procurement assistant, expecting faster responses and lower costs. What they got instead was a vendor-approval agent that stopped reading the fourth item in a list of requirements because the shorter model clipped outputs unpredictably. Procurement bottlenecks exploded. Developers panicked. Someone wondered aloud, “Do we have a way to roll back?” The silence in the room was answered enough.
That moment—an agent silently regressing—illustrates the core problem: Versioning agents isn’t about tagging code; it’s about preserving behavioral integrity.
What “Version” Should Mean for an Agent
This is where definitions get messy. When someone says “version 1.2 of the collections agent,” what exactly has changed? The prompt? The tool interface? The model weights? The dataset providing context? Or the memory schema?
Most organizations end up versioning some subset of the following:
- The Prompt or Policy Layer: The operating instructions. Often the most fragile component, it does ironically provide the least formally version-controlled.
- The Orchestration Logic: Workflow, tool hierarchy, fallback strategies—everything determining how the agent acts.
- The Underlying Model & Hyperparameters: Which LLM, which checkpoints, what temperature, what max tokens, etc.
- The Knowledge Base / Embedding Store: Every time you embed new documents or swap vector databases, the agent’s effective “world” changes.
- The Memory System: Many companies forget that memory content is a versioned artifact; if you roll back code but keep an agent’s long-term memory, things misalign fast.Tool Contracts: If a tool’s schema changes, the agent’s reasoning shifts too, sometimes subtly, sometimes catastrophically.
- Tool Contracts: If a tool’s schema changes, the agent’s reasoning shifts too, sometimes subtly, sometimes catastrophically.
Some teams try to compress all of this into one version ID. Others stubbornly keep separate versioning systems for each layer, resulting in a combinatorial explosion of “v1.4-prompt-B + orchestration-v2 + model-2025-01-15” type references that nobody can track after six months.
There isn’t a perfect answer, but the organizations that succeed tend to align on one simple philosophy: The agent version should define an exact, reproducible state of behavior at a given point in time.
If you can’t recreate the behavior, you don’t have a real version.
Rollbacks Sound Easy. They Usually Aren’t
You can revert a code commit. You can reset environment variables. You can even redeploy orchestration flows.
But roll back an agent’s behavior? That’s where things get delicate.
The moment an agent interacts with live systems, it accumulates transactional context: logs, decisions, state changes, cached embeddings, memory references, and commitments to downstream services. If you switch back to an earlier agent without reconciling this context, you get:
- Inconsistent decisions
- Partial workflows
- Duplicate automated actions
- Confusing logs that break observability
- Agents that “remember” things that earlier versions never saw
The Minimum Viable Rollback Process
Enterprises that handle agents responsibly tend to adopt a rollback workflow with at least the following ingredients:
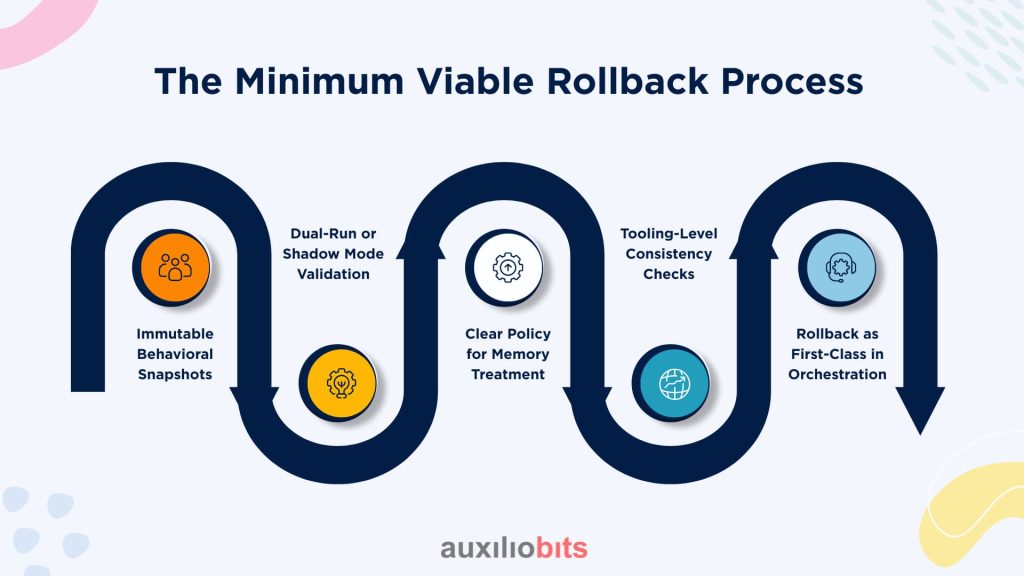
1. Immutable Behavioral Snapshots
Not just code snapshots—behavioral snapshots:
- Prompt bundle (system + developer + chain-of-thought scaffolding, if applicable)
- Tool schemas
- Model version
- Embedding dataset version
- Hyperparameters
- Memory checkpoint
Even this list is incomplete, but it’s a start. The trick is that the snapshot must be restorable without manual tuning. If you need an engineer to “tweak a few values,” it’s not a real rollback.
2. Dual-Run or Shadow Mode Validation
Before pushing a new version live, run it in parallel with the previous version:
- Feed identical inputs
- Compare decisions
- Flag divergence thresholds
Companies doing this well often use tolerances: If new agent deviates >5% from baseline actions, auto-fail the deployment.
Sure, it’s overkill for small use cases. But for agents handling finance, healthcare, or operations? You want overkill.
3. Clear Policy for Memory Treatment
This is where most failures happen. You need explicit rules on whether:
- Memory rolls back with the agent
- Memory resets entirely
- Memory is pruned
- Memory is migrated via transform scripts.
Some teams choose “no memory persistence between versions,” which is extremely safe and extremely limiting. Others create schema-versioned memory objects. Sloppy teams hope the agent “figures it out.” It usually doesn’t.
4. Tooling-Level Consistency Checks
If a tool interface changed between versions, rollback must either:
- Force reversion of the tool definition
- Reject the rollback
- Or run a compatibility adapter.
Ignoring tool compatibility is the fastest way to create zombie agents: still running, still responding, but only partially functional.
5. Rollback as First-Class in Orchestration
You shouldn’t treat rollback as an exceptional event. It should be a standard deployment instruction:
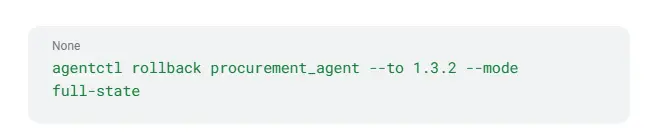
When rollback looks like this—simple, declared, consistent—you’ve hit maturity.
Why Traditional DevOps Tools Fall Short
A lot of DevOps leaders try to shoehorn agents into standard CI/CD practices. It’s understandable; they don’t want to reinvent tooling. But pipelines built for stateless microservices can’t handle:
- Multi-component agent artifacts
- Behavioral drift detection
- Reversible knowledge bases
- Memory-safe rollbacks
- Model-dependent determinism issues
Even feature flags behave oddly with agents. You can gate logic, but gating reasoning is trickier. A flag that redirects an agent to a new tool may ripple into entirely new output structures.
This is why teams are quietly building “AgentOps” stacks—some homegrown, some vendor-driven. The emerging patterns look like a blend of MLOps, DevOps, and data versioning systems like DVC or LakeFS.
Versioning Strategies That Don’t Scale (and Why)
You’ll see teams use a few popular shortcuts early on. They work… until they don’t.
1. “Version the prompt only” Strategy
This works for toy agents. It collapses as soon as you add:
- More tools
- Knowledge bases
- Multi-agent flows
- Separate operating modes
In one insurance company, they had a rule that “prompt changes require a version increment.” Then someone changed the underlying model. Then the retrieval corpus doubled. Then they added functions. Suddenly they were on “Prompt Version 44,” which meant absolutely nothing.
2. “Version the entire environment snapshot” Approach
At first glance, this seems superior. But complete state snapshots become massive and often include irrelevant artifacts. You end up with gigabytes of version bundles, most of which never need rollback. It also slows deployment to a crawl.
3. “Version nothing; rely on Git + model version history”
This almost always leads to untraceable regressions. Developers assume they can reconstruct an agent’s behavior by checking out old code and referencing the old prompt. They forget that embeddings change. Or tools changed. Or the upstream model changed. Or that an engineer tweaked a temperature parameter in staging and never updated source control.
4. “Soft versioning”: version numbers without enforcement
Common in startups. Looks neat in dashboards. Means nothing operationally.
A Practical Version Taxonomy for Agent Systems
The teams that avoid chaos typically settle on something like a four-layer versioning taxonomy. Not perfect, but workable.
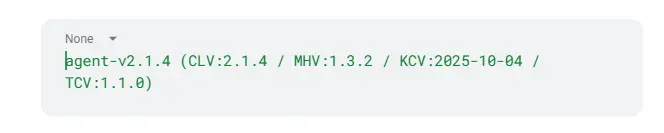
1. Layer 1—Cognitive Layer Version (CLV)
Covers
- Prompt bundle
- Reasoning patterns
- Memory logic
This is the version that most directly affects reasoning.
2. Layer 2—Model & Hyperparameter Version (MHV)
Covers:
- LLM model
- Temperature / top-p / max tokens
- Model-specific plugins
This layer shifts behavior subtly but meaningfully.
3. Layer 3—Knowledge Context Version (KCV)
Covers:
- Embedding datasets
- Retrieval configs
- Index structures
This layer shapes what the agent knows.
4. Layer 4—Tool Contract Version (TCV)
Covers
- Function schemas
- Tool authentication scopes
- Error-handling policies
This layer shapes what the agent can do.
Many organizations wrap these into a composite version string like:
Testing the Right Things: Where Teams Misjudge Risk
It’s tempting to test agents by validating outputs. “Does it produce the right text?” But that metric is shallow. You need to test much deeper aspects:
- Decision boundaries: does the agent choose tool A vs. tool B differently?
- Hallucination rates: do subtle prompt changes increase false assertions?
- Quiet regressions: the worst class when the agent seems correct but ignores edge cases.
- Does it limit sensitivity: newer prompts or models sometimes change call patterns.
- Context-length dependency: many agents fail silently when context gets too long.
The Role of Observability in Version Control
Rollbacks often happen not because the agent is wrong but because the signals around it change. An upstream API modifies a field. A database starts returning empty sets after a schema migration. Or logs suddenly stop showing expected traces.
So observability becomes a partner to version control:
- Per-version telemetry: track metrics by agent version, not just per agent.
- Divergence alerts: notify when new versions behave materially differently.
- Prompt diffs: highlight changes in operating instructions.
- Retrieval diffs: detect when the knowledge base updates.
Some teams even store semantic diffs of agent reasoning traces, although maintaining that at scale can be burdensome.
When Rollbacks Should Not Be Allowed
This may sound counterintuitive, but not all systems should permit rollbacks.
Consider:
- Agents with long-term memory tightly coupled to business events
- Agents integrated with real-time markets or pricing models
- Agents that make legally binding decisions
- Agents that generate transaction chains across distributed ledgers
Rolling back these agents can invalidate logic chains or create double counts. In these cases, forward fixes (i.e., rolling forward to a corrected version) are safer than reverting state.
Closing Thoughts
If there’s any hard truth in all of this, it’s that agent versioning isn’t glamorous. It doesn’t get applause in conferences and rarely features in vendor demos. But when ignored, it’s the single fastest route to quietly breaking core business functions.
Even mature teams occasionally forget this. They assume “the new model is better” or “the new prompt is more robust” or “the KB refresh is just additive.” That optimism usually lasts until the first agent sends a misformatted API request at 2 a.m. and an on-call engineer starts questioning all of their life choices.
Versioning and rollbacks in agent deployments don’t need to be perfect. They just need to be intentional, explicit, and behavior-aware. That’s the part most teams skip—and the part that ends up mattering the most.




