Key Takeaways
- LLM agents don’t replace legal judgement—they expose it. Their real value lies in making assumptions, precedent patterns, and risk estimates explicit. That transparency often reveals where human confidence outpaces evidence.
- Legal forecasting improves decision quality, not just win rates. The strongest use cases aren’t about predicting outcomes with certainty but about calibrating settlement strategy, resource allocation, and escalation decisions earlier—and more honestly.
- Agents succeed when they are narrow, constrained, and supervised. Systems that try to “do everything” tend to hallucinate authority or miss procedural nuance. The most effective deployments focus on specific questions embedded in real workflows.
- Clients are already more analytically mature than many firms assume. Corporate legal teams increasingly expect quantified risk discussions. Firms relying solely on intuition risk appearing outdated, regardless of pedigree.
- The challenging problems are cultural and ethical, not technical. Designing guardrails, defining accountability, and deciding when it’s irresponsible not to use probabilistic tools will shape adoption more than model accuracy alone.
Legal research has always been an odd hybrid of science and craft. On paper, it looks systematic: search precedents, read statutes, apply facts, and argue logically. In practice, it’s messier. Judgement matters. Context matters. Timing matters. And occasionally, the deciding factor is whether someone noticed a footnote in a 12-year-old appellate decision at 11:30 p.m. the night before filing.
That tension—between structure and intuition—is precisely why LLM-powered agents are showing up in legal research and litigation forecasting conversations. Instead of replacing lawyers (a claim that should already raise eyebrows), LLM-powered agents are emerging as tools that straddle the roles of junior associate, research librarian, and probabilistic analyst.
LLM-powered agents challenge decades-old habits, causing discomfort.
Also read: Designing LLM-Based Process Assistants with Task-Level Context
From keyword search to reasoning loops
Traditional legal research platforms are, at heart, retrieval engines. They index cases, statutes, regulations, commentary. You ask a question, you get documents. Even the most advanced systems still assume that the human does the real thinking: weighing authority, reconciling conflicts, and mapping precedents to facts.
LLM agents change the workflow, not just the interface.
Instead of returning a pile of cases, an agent can:
- Read dozens of decisions end-to-end
- Extract holdings and dicta
- Track how a specific legal test has evolved across jurisdictions
- Flag contradictions or unresolved splits
- Generate a reasoned synthesis, not merely a summary
That last point matters more than vendors usually admit. Lawyers don’t struggle with access to information anymore. They struggle with interpretation under time pressure.
An LLM agent, properly constrained, doesn’t “know the law.” What it does well is pattern recognition across language at scale. It can follow chains of reasoning through opinions in a way that mirrors how a mid-level associate might, minus the fatigue. Whether that output is useful depends heavily on how the agent is designed and supervised.
This is where most initial implementations encounter difficulties.
Agents, not chatbots
There’s a tendency to lump everything under “legal AI” or “GenAI for law,” as if drafting a contract clause and forecasting a motion outcome are variations of the same problem. They’re not.
An LLM agent in legal research typically has:
- A clear objective (e.g., assess likelihood of summary judgment success in a specific venue)
- Access to curated legal corporations, not the open internet
- A reasoning loop that allows it to refine hypotheses
- Guardrails around citation, authority, and confidence thresholds
- A memory or state layer to track assumptions
A chatbot answers. An agent works.
That difference becomes obvious when you ask non-trivial questions like:
“How have courts in the Ninth Circuit treated implied waiver arguments in trade secret cases post-Defend Trade Secrets Act, particularly when employee mobility is involved?”
A keyword search gives you noise. A generic LLM response gives you confident prose with questionable grounding. An agent—if built correctly—can trace doctrinal shifts, highlight fact patterns that triggered different outcomes, and admit where precedent is thin.
Admit uncertainty. That’s rare in legal tech marketing but essential in practice.
Litigation forecasting: probabilistic, not prophetic
Forecasting litigation outcomes has always existed, even if firms pretended otherwise. Partners make judgement calls about settlement ranges. Insurers price risk. General counsels ask, “What are our odds?”
Historically, this forecasting relied on experience, heuristics, and selective memory. The human brain is excellent at narrative coherence and terrible at statistical calibration.
LLM agents don’t magically correct that, but they do shift the baseline.
When combined with structured case outcome data, docket analytics, and judge-specific histories, agents can:
- Identify patterns across thousands of similar disputes
- Model how procedural posture affects outcomes
- Detect subtle signals (e.g., timing of motions, phrasing trends in judicial opinions)
- Surface non-obvious risk factors
Notice what’s missing: certainty.
The best systems produce ranges, confidence intervals, and scenario branches. If a tool claims it can “predict case outcomes with 95% accuracy”, it’s either lying or defining accuracy creatively.
Where LLM agents actually help litigators
There’s a temptation to oversell “end-to-end automation”. In reality, the most useful applications are narrow and deeply integrated into existing workflows.
Agents excel in the following areas:
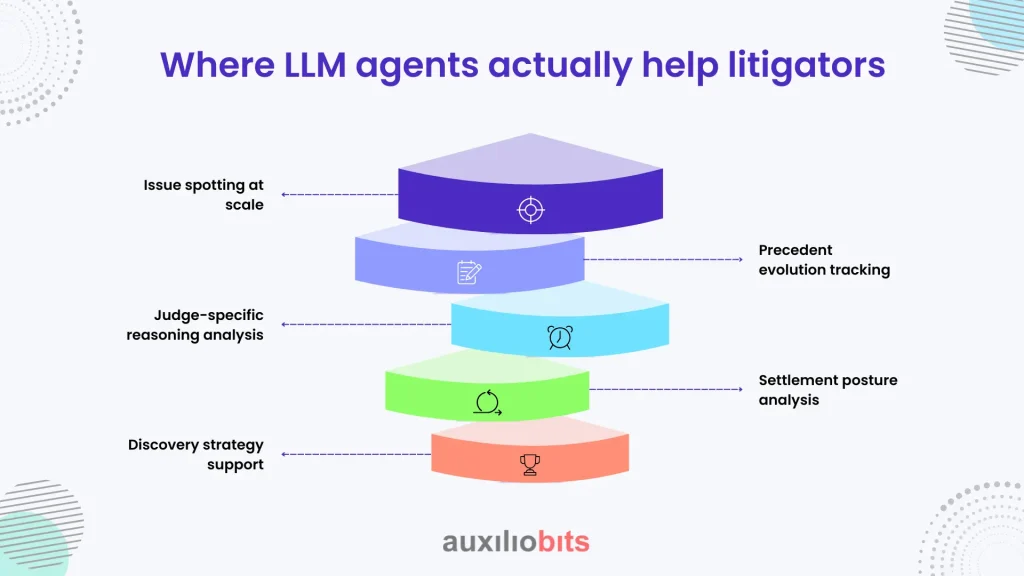
- Issue spotting at scale: Reviewing hundreds of complaints or motions to identify recurring vulnerabilities or emerging arguments.
- Precedent evolution tracking: Not just “what’s the law”, but “how courts are drifting”, which matters in unsettled areas.
- Judge-specific reasoning analysis: Parsing language patterns in prior opinions to understand how a judge frames certain doctrines.
- Settlement posture analysis: Comparing fact patterns against historical settlement outcomes, not just trial verdicts.
- Discovery strategy support: Mapping likely evidentiary pressure points based on similar cases.
The quiet shift inside law firms
What’s intriguing isn’t just adoption, but who is pushing for it.
In many firms, it’s not innovation committees or managing partners. It’s senior associates and counsel who are tired of spending nights reconciling conflicting lines of authority. They know the work is necessary, but they also know it’s not where their judgement adds the most value.
There’s also a less discussed dynamic: clients are becoming more sophisticated. Corporate legal departments now run their own analytics. When outside counsel shows up with nothing but intuition, it shows.
An agent-backed analysis—clearly labeled as probabilistic, clearly supervised—changes that conversation. It doesn’t eliminate debate. It anchors it.
Where this goes next
Some trajectories seem likely:
- Agents will become standard in early case assessment, not exceptional.
- Clients will expect quantified risk discussions, not just narratives.
- Courts will indirectly influence models through writing styles and opinion structure.
- Legal education will lag, then scramble to catch up.
What won’t happen overnight is full automation of legal reasoning. Law resists that, not because it’s old-fashioned, but because it’s socially embedded. Doctrine doesn’t exist in isolation from politics, economics, and human values.
LLM agents are powerful precisely because they sit at the boundary: translating vast textual histories into usable signals, without pretending to resolve normative questions.
Used well, they make lawyers sharper. Used poorly, they make mistakes faster.
And that, in some ways, is the most honest summary you can give.