




Key Takeaways
- Supply chain exception automation is about response speed, not just better alerts. Detection alone doesn’t prevent operational damage—timely intervention does.
- Delay handling requires contextual intelligence. Not every delay deserves escalation; autonomous agents differentiate based on downstream impact.
- Re-routing decisions are multi-variable trade-offs. Cost, capacity, contractual exposure, and inventory buffers must be evaluated simultaneously—something humans struggle to do at scale.
- Autonomous agents reduce decision latency, not human relevance. Planners shift from reactive problem-solvers to supervisory controllers of automated execution.
- Resilience improves when exceptions are absorbed early. The goal isn’t eliminating disruptions—it’s preventing small delays from cascading into systemic failures.
Supply chains don’t break during planning. They break on Tuesday afternoons when a truck misses its slot in Rotterdam. Alternatively, a supply chain can break at 2:17 AM when a container is unexpectedly flagged at customs. Alternatively, they can occur when a supplier inadvertently delays a shipment by 48 hours, a situation that goes unnoticed until the production schedule begins to collapse.
These moments—exceptions—are where the real cost lives.
Most supply chain leaders already understand this intellectually. They’ve invested in visibility platforms, control towers, and dashboards. Yet exceptions still slip through. This is not due to the systems’ inability to detect them. The real issue lies in the fact that detection was never the primary issue. The response is.
This is where supply chain exception automation, driven by autonomous agents, is quietly reshaping operations—not by providing better dashboards, but by removing human latency from delay handling and re-routing decisions.
And that distinction matters more than most teams initially realize.
Also read: Supply Chain Visibility: Why Dashboards Are Not Enough
Exceptions Are Not Rare Events. They Are the System
If you look closely at any moderately complex logistics network, you’ll notice something uncomfortable: exceptions aren’t exceptions. They’re the baseline condition.
Weather disruptions. Port congestion. Labor shortages. Equipment imbalances. Carrier capacity fluctuations. Customs inspections. Inventory mismatches. Production delays upstream.
At a global scale, something is always wrong. Even highly optimized organizations like Maersk operate in an environment where schedule reliability can drop below 70% depending on trade lanes. That means nearly one in three shipments deviates from its planned execution.
Yet most organizations still handle exceptions manually.
A planner notices a delay alert.
They investigate.
They check downstream dependencies.
They email or call carriers.
They escalate if needed.
They decide whether to expedite, re-route, or absorb the delay.
Each step introduces delay. Not shipping delay—decision delay. And decision delay is often more expensive than the physical disruption itself.
Traditional Exception Management Is Fundamentally Reactive
Most supply chain control towers work like notification engines. They identify anomalies and notify humans.
Which sounds useful. And it is—to a point. But there’s a structural limitation. Notifications do not resolve anything.
They shift cognitive workload to already overloaded planners.
Consider what actually happens when a shipment delay alert appears:
- Someone must verify whether the delay is real or transient
- They assess the shipment’s criticality
- They evaluate downstream impacts (production lines, customer deliveries, and warehouse scheduling).
- They explore alternatives (expedite, re-route, split shipments, reallocate inventory)
- They execute corrective actions across multiple systems
This can take hours. Sometimes days. Meanwhile, the system continues moving toward failure. The uncomfortable truth is this: visibility without action simply accelerates awareness of failure.
Automating supply chain exceptions changes this by enabling autonomous response—not just autonomous detection.
Autonomous Agents Shift Exception Management from Monitoring to Intervention
Autonomous agents don’t just observe disruptions. They actively participate in operational recovery.
They ingest real-time signals from:
- Transportation management systems
- Carrier APIs and GPS feeds
- Warehouse execution systems
- Production planning systems
- Weather and port congestion data
- Inventory and order management platforms
But more importantly, they understand relationships. They know which shipments feed which production orders.
Which customers are sensitive to delays?
Which alternate routes exist?
Which carriers are contractually available?
Which actions increase cost versus prevent downstream loss?
This contextual awareness enables autonomous decision-making. Not theoretical decision-making. Executable decisions.
Delay Handling: Where Autonomous Exception Automation Creates Immediate Value
Delay handling is the most common—and expensive—exception category.
Not all delays are equal. A 12-hour delay on safety stock replenishment might not matter. A 6-hour delay on production-critical material can shut down an assembly line.
Autonomous agents distinguish between these scenarios automatically.
When a delay signal appears, agents immediately evaluate:
- Downstream production dependencies
- Inventory buffers and safety stock levels
- Customer delivery commitments
- Contractual penalty exposure
- Alternate sourcing or transportation options
They don’t escalate everything. That would recreate the same bottleneck with different technology.
Instead, they intervene selectively.
For example: A Tier-1 automotive supplier in Eastern Europe faced recurring inbound material delays due to port congestion.
Traditionally, planners discovered delays 8–16 hours after occurrence. The response required another 4–6 hours.
Autonomous exception automation reduced decision latency to under 10 minutes.
The reduction in decision latency was not due to faster transportation. This was due to the early initiation of corrective action.
This included:
- Automatically reallocating buffer inventory between plants
- Securing alternate trucking capacity before shortages materialized
- Adjusting production sequencing to absorb delays without stoppage
Production disruptions dropped significantly—not eliminated, but reduced enough to change operational stability.
That distinction matters. Perfection isn’t the goal. Stability is.
Re-Routing Decisions: More Complex Than They Appear
Re-routing sounds straightforward in theory. Shipment delayed → choose alternate route → execute. In reality, re-routing decisions involve multiple trade-offs.
Cost versus speed.
Contractual obligations versus operational necessity.
Warehouse capacity constraints.
Customs clearance implications.
Carrier reliability differences.
Human planners consider these factors intuitively—but slowly. Autonomous agents evaluate them continuously.
When disruption occurs, agents assess options such as:
- Switching from ocean to air for partial shipment quantities
- Re-routing through alternate ports with lower congestion
- Splitting shipments across multiple carriers to reduce risk concentration
- Redirecting shipments to alternate warehouses closer to demand centers
But they don’t blindly optimize for speed. Sometimes the cheapest option is correct.
Sometimes absorbing the delay is less harmful than rerouting. This nuance is where supply chain exception automation proves its maturity. Specifically, if naive automation overreacts to every disruption, it can actually increase costs.
Well-designed autonomous agents incorporate business priorities—not just logistical metrics.
Real-World Scenario: Re-Routing That Prevented a Cascading Failure
A consumer electronics manufacturer faced recurring inbound shipment delays from Southeast Asia during peak season. One delayed container carried a critical component used in multiple product lines.
Traditional handling would have escalated to planners during business hours. Re-routing decisions would likely occur after production scheduling was already impacted.
Instead, autonomous exception automation intervened immediately.
The agent:
- Identified production lines dependent on the delayed component
- Calculated projected shortage timelines
- Located alternate inventory at another distribution center
- Initiated partial inventory transfer via expedited trucking
- Re-sequenced production schedules automatically
Notably, it did not expedite the entire shipment via air freight. That would have cost significantly more. Instead, it used localized inventory redistribution to bridge the gap. The delayed shipment eventually arrived. No production shutdown occurred. The savings weren’t just transportation cost avoidance. These savings also included avoided downtime, avoided rescheduling chaos, and avoided disruptions in downstream delivery. These second-order effects often dwarf the direct logistics cost.
Why Human-Driven Exception Management Struggles at Scale
Humans excel at judgment. But they don’t scale infinitely. A single planner can effectively manage maybe 40–60 critical shipments simultaneously. Beyond that, cognitive overload sets in.
Signals get missed. Response slows. And modern supply chains easily involve thousands of active shipments.
Autonomous agents scale differently. They evaluate every shipment continuously, without fatigue or prioritization bias.
This enables capabilities humans simply cannot replicate operationally:
- Continuous exception monitoring at full network scale
- Immediate decision evaluation without queue delays
- Parallel response execution across multiple disruptions
- Consistent adherence to operational policies
It’s not about replacing planners. It’s about removing their role as bottlenecks. Planners shift from firefighting to supervisory control. Frankly, this is the area where they add the most value.
The Architecture Behind Supply Chain Exception Automation
Effective supply chain exception automation depends on more than AI models. It requires coordinated system integration and execution authority.
Core components typically include:
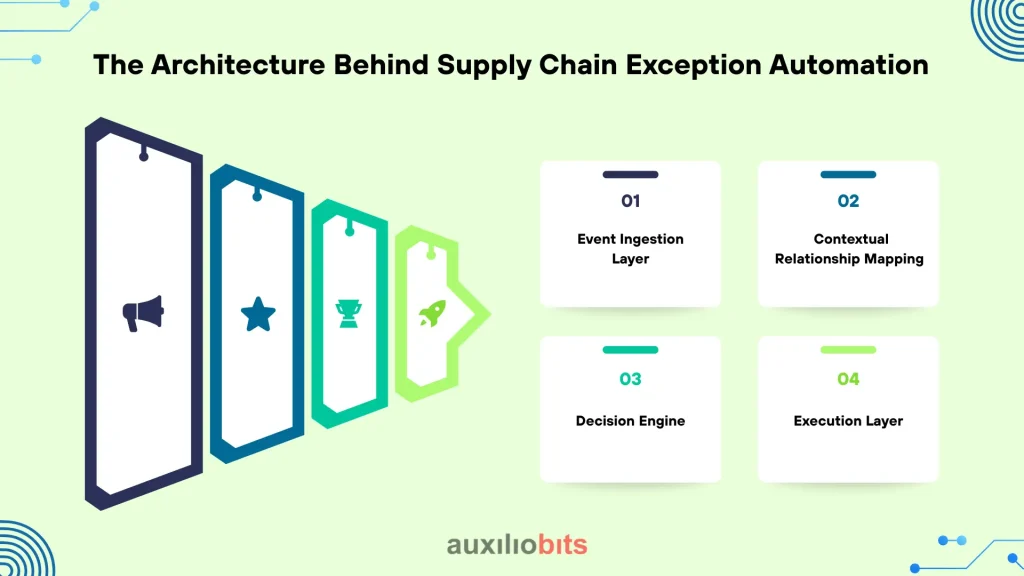
1. Event Ingestion Layer
Captures disruption signals from across the ecosystem.
Sources include:
- Carrier telematics
- Port status feeds
- ERP shipment status updates
- IoT sensor telemetry
- External risk signals
Without timely event capture, autonomous response becomes irrelevant.
Latency matters.
2. Contextual Relationship Mapping
This is often overlooked.
Agents must understand relationships between:
- Shipments and production orders
- Shipments and customer commitments
- Shipments and warehouse operations
Without this, agents cannot prioritize intelligently.
This is where many early exception automation initiatives fail—they automate alerts without automating context.
3. Decision Engine
This evaluates corrective options.
It considers:
- Operational impact severity
- Available alternate routes
- Inventory redistribution possibilities
- Cost implications
- Contractual constraints
Importantly, decisions are not static. They evolve as conditions change.
4. Execution Layer
This is the critical difference between automation and analytics.
Agents must be able to:
- Book alternate transportation
- Modify shipment routing instructions
- Update ERP and TMS records
- Notify stakeholders
Without the ability to execute, automation is limited to providing recommendations, which still require human intervention. True supply chain exception automation completes the loop.
Where Autonomous Exception Automation Still Struggles
It would be misleading to present autonomous agents as universally flawless. There are real limitations. Data quality remains the biggest constraint. If carrier status updates are delayed or inaccurate, autonomous response can be misaligned.
Organizational trust is another challenge. Operations teams often hesitate to grant execution authority to automated systems—especially early on. No one wants automation making expensive mistakes. There’s also a subtle risk of over-optimization. Agents optimizing purely for cost might inadvertently increase operational risk exposure. This is why business rules and guardrails remain essential. Autonomy requires boundaries. Not everything should be automated equally.
The Measurable Impact of Exception Automation on Supply Chain Performance
Organizations implementing supply chain exception automation consistently see improvements across multiple dimensions: Operational stability improves through faster response.
Cost leakage decreases due to proactive mitigation rather than reactive escalation. Service levels improve because fewer disruptions propagate downstream.
Key performance improvements often include:
- Reduction in shipment delay impact severity
- Lower expedited freight spending
- Improved on-time delivery performance
- Reduced manual intervention workload
- Faster recovery from disruptions
Retailers like Walmart have invested heavily in automated logistics orchestration for exactly this reason—not to eliminate disruption, but to reduce disruption consequences.
This is where the true battle lies. Disruptions will always exist. The goal is minimizing their operational impact.
Practical Implementation Realities: What Works
Organizations succeed with supply chain exception automation when they take a pragmatic approach.
Not everything needs full autonomy immediately.
Effective strategies often include:
- Start with high-impact exception categories (production-critical shipments)
- Automate low-risk corrective actions first
- Gradually expand execution authority as trust builds
- Maintain human oversight during early deployment phases
- Integrate automation into existing TMS and ERP workflows
Most importantly, focus on response speed. Speed matters more than algorithmic sophistication. A simple corrective action executed immediately often beats a theoretically optimal action executed hours later. Timing is everything in exception management.
The Operational Shift: Exception Management Becomes Continuous Instead of Episodic
Traditional exception management is episodic.
Detect → escalate → respond → recover.
Autonomous exception automation transforms it into continuous operational correction. Agents constantly monitor, evaluate, and adjust execution in real time. Exceptions don’t accumulate. They get absorbed. This fundamentally changes supply chain resilience. Not by eliminating disruption—but by reducing disruption amplification. This, from an operational perspective, is what ultimately leads to supply chain failure. Not the initial delay. The delayed response. And once response latency disappears, supply chains behave very differently. More stable. More predictable. Less fragile. Not perfect. But far more controllable. That difference defines the next generation of supply chain execution.

