In manufacturing and industrial operations, downtime is not only inconvenient – it is expensive. A stalled production line or a malfunctioning pump can cascade into the left deadline, waste material, and disappointed customers. Companies have long trusted scheduled maintenance or reactive repair, but these approaches often lag behind real problems. Machines rarely fail on schedule, and production can already be interrupted until a mistake is made.
Then comes an anomaly detection system operated by an NVIDIA GPU. These systems are not just another layer of monitoring – they are designed to analyze large-scale sensor data in real time, identifying subtle warning signals that can miss humans or traditional systems.
Also read: Conversational agents as service: combining LLMs, NVIDIA GPU clouds, and Azure/AWS endpoints
Why Downtime Still Happens
Even with advanced machinery, downtime is surprisingly frequent. Consider the oil and gas field, where the failure of an electric submersible pump (ESP) can exceed $150,000 per day. Similarly, in motor vehicle manufacturing, via unexpected stagnation, supply chains in assembly lines can be waived through by delaying delivery and increasing operating costs.
Time-based maintenance programs may not be responsible for the random nature of mechanical failures. Reactive maintenance is even less ideal: repair occurs only after a mistake appears. Both approaches are naturally disabled and expensive. What is needed is a system that estimates issues before disrupting production.
Why GPUs Make a Difference
The reason for detecting the modern GPU discrepancy lies in their architecture. Unlike the CPU, which gradually processes the functions, the GPU excels in handling thousands of calculations simultaneously. This equality is particularly useful to analyze sensor readings from industrial devices, which can stream millions of data points every hour.
An NVIDIA GPU-operated agent can process this high-vantage, high-veg data in real time. Instead of reacting to visual failures, the system detects subtle deviations in vibration, temperature, or pressure—small signs that a component may soon fail.
A Practical Model: NV-Tesseract
An example of this type of system is the NV-Tessellation of NVIDIA. Designed for time-series data, it uses a transformer-based model to catch relationships in long sequences. This capacity is important: a temperature spike after fluctuating under pressure may not look unusual in spike isolation, but together they may indicate an adjacent failure.
In practice, NV-Terract has been used in manufacturing plants to monitor CNC machines, motors, and pumps. Engineers report that it can mark potential defects for hours or even days, even before traditional monitoring. This initial warning gives the maintenance teams an opportunity to intervene during employed downtime, avoiding production stops.
Predictive Maintenance in Action
The future maintenance is no longer theoretical – this is the result of the average.
- General Motors deployed AI-Pausti Future Systems to monitor the assembly line machinery. By analyzing historical and real-time sensor data, the system estimated failures with much more accuracy than the traditional program. As a result, GM reduced unplanned downtime, which translated to rapid production cycles and low maintenance costs.
- Baker Hughes in the oil and gas fields faced high false alarm rates with classical surveillance methods for ESPs. After introducing the deep learning model running on the NVIDIA GPU, the company achieved 93% detection accuracy and a month’s lead time, with a false alarm rate of just 5%. Financial impact was important to avoid millions in potentially lost revenue.
These examples highlight a key insight: the real value isn’t just in detecting failures, but in detecting them early enough to take meaningful action.
Challenges and Nuances
Even the most powerful discrepancy system is not a magic wand. Many practical ideas determine whether it is successful:
- Data Quality: Garbage, garbage out. If the sensor is incorrectly, malfunctioned, or rare, the detecting agents can produce false positives – or worse, important warnings. Regular calibration and thoughtful sensor placements are required.
- Integration Complexity: Heritage machinery does not always communicate easily with modern AI systems. IT and operating teams need to cooperate closely to integrate GPU-operated agents without disrupting production.
- Skill Requirements: Installing and maintaining these systems demands specialization in machine learning, data engineering, and GPU programming. Organizations should bring either special staff or external experts, which can affect the adoption deadline.
It is also worth noting that while the detection of GPU accelerates, they are not always cost-effective for small-scale operations. For plants with limited equipment, cloud-based solutions or a hybrid setup can provide a better balance between performance and expenditure.
Observations from the Field
GPU-Industrial deployment of the detection of operational discrepancy has revealed several nuances:
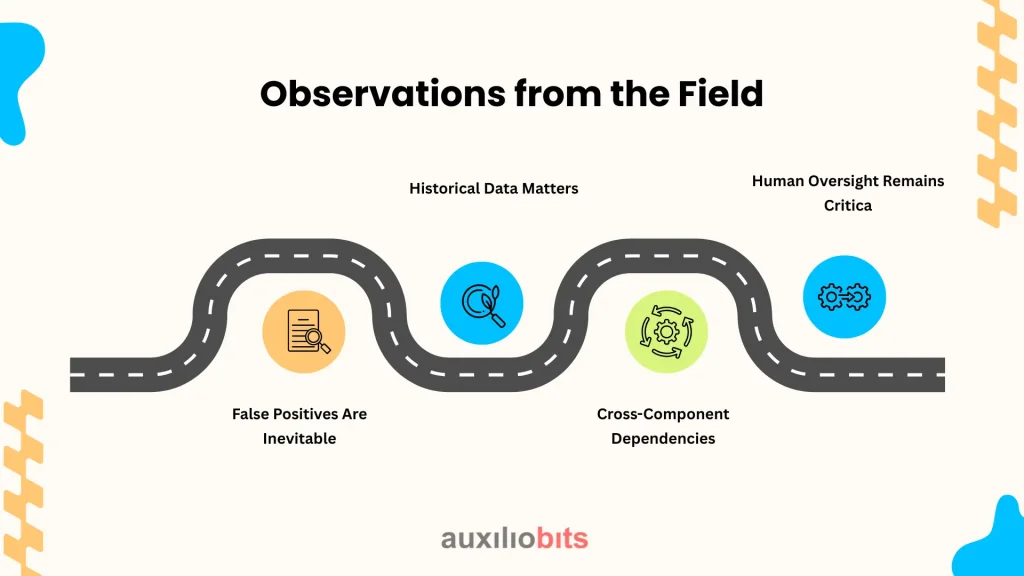
- False Positives Are Inevitable: Even with deep education, not every discrepancy requires intervention. Maintenance teams should calibrate the threshold and understand which alerts are capable.
- Historical Data Matters: With a rich historical dataset, the future model is equally accurate. Machines with rare historical records may require an initial period of observation before the predictions are reliable.
- Cross-Component Dependencies: Sometimes, a discrepancy in an ingredient triggers a series of reactions elsewhere. Advanced models can capture these dependencies, but simplified setups can ignore them.
- Human Oversight Remains Critical: AI can suggest, predict, and give priority, but experienced engineers still need to validate alerts and call decisions.
These subtleties throw light on the fact that while the GPU-operated identity is powerful, it is not a complete replacement for efficient human operators. Instead, it enhances their effectiveness, making teams focus on the most important interventions.
Looking Ahead
The industrial space is slowly moving towards the future of data-driven maintenance. GPU-operated discrepancy agents are already proving their value, not only proof-of-conceptuality but also in the real production environment.
Organizations adopting these systems get more than low downtime. They also achieve:
- Detected production scheduled
- Low maintenance cost
- Extended equipment lifetime
- Increased safety, as initial detection can prevent frightening failures
However, careful planning is required to feel these benefits: ensuring high-quality sensor data, integrating with existing operations, and developing in-house expertise. When these challenges are effectively navigated, companies can expect an average improvement in productivity and competition.
Conclusion
Downtime will always be a threat in manufacturing and industrial operations, but the way organizations handle it is changing. NVIDIA GPU-powered anomaly detection agents demonstrate that predictive maintenance is no longer a distant vision but a practical, high-impact reality. By processing enormous streams of sensor data in real time, these systems identify weak signals that traditional monitoring would miss—offering maintenance teams the precious advantage of time.
The takeaway is clear: success doesn’t lie in simply deploying AI, but in building the right ecosystem around it—reliable data pipelines, thoughtful integration with existing equipment, and skilled teams who can act on the insights. Companies that embrace this approach will not only reduce downtime but also extend asset lifespans, safeguard worker safety, and strengthen their competitive edge in markets where efficiency is everything.
As GPU-powered intelligence continues to mature, the industrial enterprises that invest early will be the ones defining the new standard of resilience and reliability in the years ahead.