Key Takeaways
- Conversational agents aren’t just “plug in an LLM.” Real deployments rely on a three-layer stack: reasoning models, NVIDIA GPU infrastructure, and enterprise endpoints from Azure or AWS.
- NVIDIA remains the backbone of inference. Despite talk of alternatives, CUDA tooling, batching optimizations, and cloud neutrality keep GPUs at the center of production systems.
- Cloud providers add governance, not just compute. Azure and AWS endpoints matter because they deliver security, compliance, and enterprise integration that raw GPU clouds cannot.
- Latency defines user trust. Even the most intelligent model fails if replies exceed ~2.5 seconds; architectural choices must fit within human patience budgets.
- Hybrid strategies are messy but inevitable. Most enterprises blend open-source LLMs on GPU clouds with managed cloud endpoints, accepting operational complexity as the price of flexibility.
Building conversational systems used to mean hiring a small army of linguists, annotators, and engineers who hand-crafted intents and rules. Anyone who worked with the early iterations of Dialogflow, LUIS, or IBM Watson Assistant remembers the brittle nature of those flows. They were good for FAQs and transactional prompts, but collapsed under ambiguity. Fast forward to now, and the phrase “conversational agent” almost always implies a large language model (LLM) under the hood. Yet deploying one in production is not as trivial as dropping OpenAI’s API into a web form. Enterprises that run regulated workloads—or those with latency, privacy, or cost constraints—are learning that it requires a careful orchestration of model endpoints, GPU infrastructure, and cloud services.
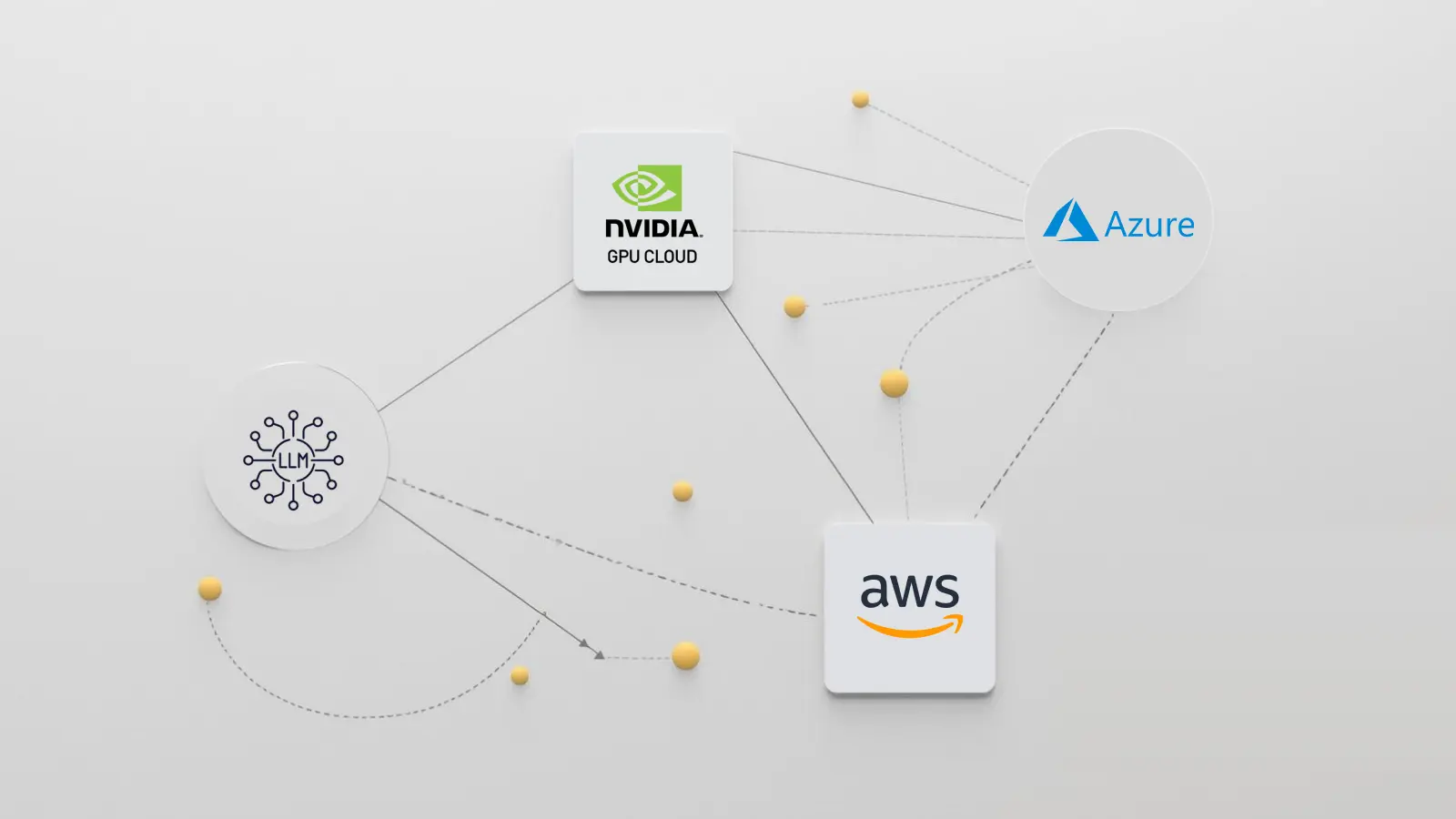
This is where “conversational agents as a service” emerges: not a monolithic platform, but a mesh of specialized layers—LLMs for reasoning, NVIDIA GPU clouds for horsepower, and Azure/AWS endpoints for scale and compliance. The interesting part isn’t the buzzwords themselves, but how these layers cooperate (and sometimes fight) in real deployments.
The Layers of Modern Conversational Service Architectures
When enterprises ask vendors for a “chatbot,” they’re rarely just buying text completion. They’re buying an ecosystem. At a minimum, three moving parts dominate:
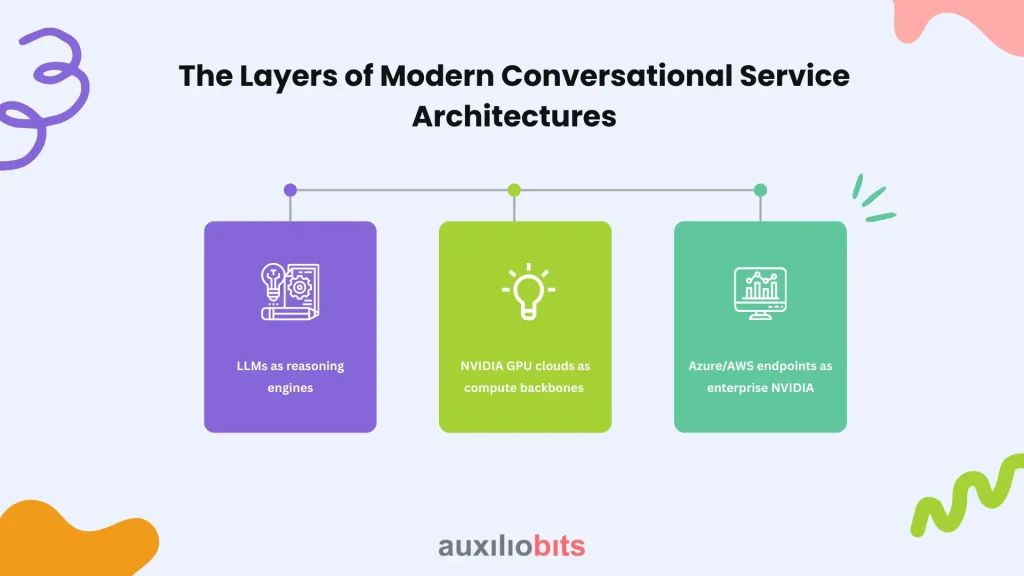
1. LLMs as reasoning engines
- GPT-4, Claude, or open-source families like LLaMA and Mistral.
- These models give fluency, contextual understanding, and adaptability—but they’re heavy and need orchestration.
2. NVIDIA GPU clouds as compute backbones
- Whether it’s A100s, H100s, or increasingly L40S units, these GPUs are not just about raw FLOPs. They dictate concurrency limits, inference speed, and ultimately, per-interaction economics.
3. Azure/AWS endpoints as enterprise NVIDIA
- Azure ML endpoints, AWS SageMaker hosting, or even API Gateway + Lambda.
- These deliver governance, compliance certifications (HIPAA, FedRAMP, SOC2), and integration with enterprise identity (AD/SSO).
The interplay of cost, control, and compliance doesn’t always align seamlessly. For example, while many find Azure OpenAI’s managed GPT appealing due to its compliance assurances, the per-token pricing can become concerning when call volumes surge. Conversely, their data science team might utilize fine-tuned LLaMA-3 on rented Nvidia clusters, achieving half the unit cost. However, this approach can lead to procurement issues due to vendor lock-in from GPU providers. This illustrates the inherent real-world tension among these three critical factors.
Why Nvidia Still Dominates the Stack
Every so often, you’ll see a headline about “TPUs beating GPUs” or “custom silicon challenging NVidia.” In practice? Ninety percent of production conversational services run on NVidia silicon. Why?
- Ecosystem gravity. CUDA, TensorRT, and Triton Inference Server—these aren’t just tools, they’re moats. Once your team optimizes inference pipelines with CUDA kernels, migrating to another accelerator becomes a six-month engineering project.
- Throughput economics. For conversational agents, latency matters more than throughput. NVidia’s work on batching inference requests means a bank running 50 concurrent chats doesn’t need 50 GPUs—it needs careful scheduling.
- Cloud neutrality. AWS, Azure, and GCP all build GPU-based services on NVidia hardware. That reduces the lock-in anxiety (ironically) because the same model can be containerized and redeployed across providers.
The irony here is palpable: everyone claims to want open, portable conversational AI, but they keep writing CUDA-specific kernels because that’s the only way to hit SLA targets.
Azure and AWS: Not Just Compute Providers
Azure and AWS offer more than just GPU resale; their true value lies in governance and integration, rather than mere compute cycles.
- Security wrappers. When a financial services client deploys conversational agents, regulators don’t ask about token embeddings—they ask where data is encrypted, where logs are stored, and who has access. Azure’s Confidential Compute and AWS Nitro Enclaves solve problems that raw GPU clouds can’t touch.
- Enterprise glue. Imagine an agent that needs to query an ERP for purchase orders. Through AWS PrivateLink or Azure VNet injection, that call can stay inside the enterprise perimeter. Without that, every query traverses the public internet—unacceptable in pharma or defense.
- Scalable endpoints. SageMaker and Azure ML Online Endpoints enable the deployment of auto-scaling inference through a managed API. This eliminates the need for businesses, such as e-commerce firms, to manage Kubernetes for handling fluctuating traffic during peak seasons.
While the cost of GPUs, orchestration, monitoring, and compliance layers can lead to what some CFOs term a “cloud tax,” this perspective often underestimates the significant expense of establishing and maintaining comparable in-house safeguards.
Case Example: Retail Contact Center Modernization
Consider a global retail brand replacing its legacy IVR system. Their goals: reduce call center wait times, triage queries automatically, and surface recommendations to human agents when escalation is needed.
- LLM choice. They fine-tuned a 13B open-source model to reduce hallucinations in product names and SKU lookups.
- GPU infra. Training ran on NVidia A100 clusters rented through CoreWeave, but inference was containerized with Triton to run on Azure’s GPU VMs.
- Endpoint integration. Azure ML Online Endpoints wrapped the model with enterprise authentication, logging, and integration into Dynamics 365 CRM.
The result: first-call resolution improved by 22%. Interestingly, the biggest win wasn’t cost reduction but employee retention—human agents stopped dealing with repetitive “where’s my order” queries and instead focused on complex cases.
This illustrates a point: ROI in conversational agents isn’t always about saving money. Sometimes it’s about not burning out your workforce.
Patterns That Work, and That Fail
Not all architectural choices succeed. A few field notes from the last two years:
Work well:
- Offloading heavy reasoning to centralized GPU clusters, while keeping lightweight entity extraction local for latency.
- Using vector databases (Pinecone, Cosmos DB, Aurora with pgvector) alongside LLMs for retrieval dramatically reduces hallucinations.
- Splitting orchestration logic into a thin agent layer (LangChain, Semantic Kernel) instead of embedding it deep inside business logic.
Fail often:
- Overfitting on fine-tuning. Teams burn months retraining models when prompt engineering plus retrieval would have sufficed.
- Ignoring cost per conversation. Some enterprises discover too late that their “$0.002 per token” translates to millions annually at call-center scale.
- Treating endpoints as black boxes. Blindly piping sensitive data into managed endpoints without redaction or masking has led to compliance nightmares.
The failures are usually cultural, not technical: teams assume the cloud provider handles everything. In reality, Azure or AWS secures the infrastructure, but you still own prompt filtering, logging retention, and data governance.
The Impact of Delay on Conversations
Conversational design harbors a harsh truth: users will not tolerate a response delay exceeding approximately 2.5 seconds, beyond which they perceive the system as “broken.” This tight latency constraint presents a significant challenge for enterprise implementations.
- Model inference: 800 ms
- Network overhead: 300 ms
- Logging, security, middleware: 700 ms
- UI rendering on a mobile app: 400 ms
Losing those crucial 2.2 seconds makes an AI agent feel slow, regardless of its intelligence. This highlights why GPU optimization techniques like quantization, batching, and distillation are vital; they directly influence user experience. Some teams employ a two-tiered model approach: a compact, distilled model handles rapid responses, while a more extensive model operates in the background for deeper context. Users remain unaware of this sophisticated setup, yet they perceive the seamless speed.
Where Things Get Messy: Multi-Cloud and Hybrid
Most enterprises don’t pick a single path. They end up with a strange mix: fine-tuned open-source LLMs on NVidia clusters in one region, while also consuming Azure OpenAI for sensitive workflows. This hybrid approach creates headaches:
- Latency mismatches. Queries routed across clouds hit unpredictable bottlenecks.
- Billing sprawl. Finance teams struggle to reconcile GPU invoices from one vendor and token-based invoices from another.
- Governance silos. Compliance checks must be duplicated across environments.
Many CIOs accept this situation, despite the operational chaos, because no single vendor offers a complete solution. This complexity ironically serves as a way to diversify vendor risk. As one European bank’s CIO explained, “If Azure changes terms tomorrow, at least we can fall back on our GPU contracts.”
Practical Guidance for Enterprises
For B2B leaders evaluating conversational agents as a service, a few grounded takeaways:
- Don’t optimize purely for model accuracy. Evaluate economics per conversation and end-user latency budgets.
- Treat NVidia GPU capacity as a scarce resource, especially during global supply crunches. Secure contracts early.
- Use cloud endpoints for workflows that require compliance and integration; reserve custom GPU clusters for experimentation or cost-sensitive inference.
- Build a minimal observability layer from day one: logging prompts, responses, latency metrics. It’s astonishing how many projects skip this until regulators come knocking.
- Plan for constant iteration. Unlike static RPA bots, conversational agents drift. Language changes, regulations evolve, and models degrade without monitoring.
The Final Verdict
While it’s appealing to envision a straightforward progression towards seamless enterprise AI assistants, the actual development is more inconsistent. Some implementations excel, significantly improving productivity and user satisfaction. Conversely, others struggle with issues like latency, compliance, or a disconnect between vendor assurances and real-world enterprise needs. The technology is undoubtedly potent, yet it remains complex. Perhaps the most accurate perspective is to view conversational agents not as a final product for purchase but rather as an ongoing service that requires careful management.