Key Takeaways
- Jetson’s value isn’t raw GPU power—it’s edge preprocessing. By transforming unstructured sensor data into structured event logs before transmission, Jetson prevents warehouses like Synapse or Redshift from drowning in petabytes of noise.
- The true bottleneck is semantic mismatch, not bandwidth. Reconciling event streams from edge devices with ERP, CRM, or supply chain schemas is the hardest part of integration. Governance and metadata alignment matter more than raw throughput.
- There’s no single winning pipeline pattern. Direct streaming, staging in storage, event brokers, or hybrid inference all work in different contexts. Naive nightly CSV uploads almost always collapse at scale.
- Synapse and Redshift are not interchangeable. Synapse is stronger in Azure IoT-heavy environments; Redshift excels in AWS-first ecosystems with S3 as the backbone. The choice often reflects enterprise context, not just features.
- Edge-to-cloud is as much organizational as technical. Schema governance, security models, latency vs. fidelity trade-offs, and team alignment decide success more than hardware or cloud services do.
When engineers talk about “edge-to-cloud” data architectures, the conversation often splits into two camps. On one side, hardware people who obsess over thermal envelopes, power budgets, and whether Jetson Xavier or Orin can run a real-time inference workload in a dusty factory corner without throttling. On the other hand, cloud architects immediately want to know how fast you can move parquet files into Synapse pipelines or Redshift clusters, and how you keep the schema stable.
Both are right, and both miss the real problem: coordinating edge intelligence with cloud-scale analytics isn’t just about speed or capacity. It’s about trust—whether you can trust the data as it flows, whether you can trust the models that act on it locally, and whether your enterprise can trust that the entire pipeline won’t collapse under the weight of brittle integrations.
Also read: Cost‑optimization strategies: spot GPU pricing (AWS, Azure NVidia) for training and inferencing
Why Jetson Is Not Just Another Edge Device
NVIDIA’s Jetson line isn’t simply a GPU squeezed onto a compact board. It’s an inference platform designed for edge-first decisions. You see them in autonomous drones, warehouse robotics, smart traffic cameras, and even portable medical devices.
What makes Jetson relevant in the edge-to-cloud conversation is its ability to preprocess messy sensor inputs before they hit the WAN. A Jetson Xavier NX running TensorRT-optimized models can reduce raw video to structured object detection logs. Instead of sending 50 MB per second of unfiltered video, you might only push JSON event packets: “vehicle detected, class=truck, confidence=0.94, timestamp=…” That’s a hundredfold reduction in payload before the first hop to your cloud landing zone.
This matters. Cloud data warehouses like Synapse and Redshift are not designed to be dumping grounds for petabytes of raw telemetry. They shine when fed semi-structured or structured data streams that align to fact/dimension tables or columnar partitions
The Real Coordination Challenge
People think the bottleneck is bandwidth. It isn’t—at least not always. A bigger issue is semantic mismatch. Edge devices outputting event streams don’t always line up with how business analysts query data in Synapse or Redshift.
Example:
- A Jetson-powered vision system counts pallets moving across a loading dock.
- Operations managers want to compare this count to ERP shipment records.
- Data warehouse tables are organized by shipment IDs, customer accounts, and carrier codes.
The edge device doesn’t know anything about ERP semantics. It just sees “object type: pallet.” Somewhere between the edge and the warehouse, metadata needs to be enriched, keys need to be joined, and event streams need to be reconciled with master data.
That’s where coordination—not just transport—becomes the issue.
Patterns That Work
Over the last few years, several integration patterns have emerged. Some are promising; others turn out brittle.
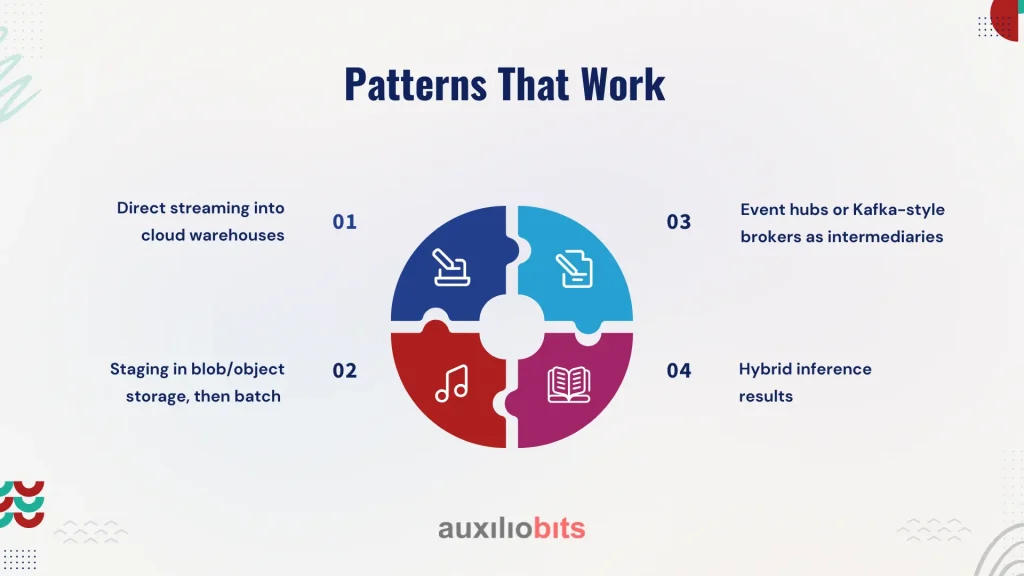
Direct streaming into cloud warehouses
- Works well for IoT metrics with simple time-series structures.
- Breaks down when schema evolution occurs (Jetson model version 1 vs. version 2 produces slightly different fields).
Staging in blob/object storage, then batch ETL
- Common in AWS setups: Jetson → Kinesis Firehose → S3 → Redshift COPY.
- Reliable, but introduces latency. If you’re okay with “yesterday’s insights,” it’s fine. If you need to react in five minutes, it’s not.
Event hubs or Kafka-style brokers as intermediaries
- Azure Event Hubs or MSK in AWS absorb bursts from the edge.
- Adds resilience and replay, but creates another moving piece that ops teams have to maintain.
Hybrid inference results
- Jetson runs inference but also logs “confidence < threshold” cases to the cloud for reprocessing.
- Nuanced but powerful—you get low-latency autonomy with a feedback loop for continuous model improvement
Notice what doesn’t work well: naive file dumps. There have been organizations that try “Jetson writes CSV, scp to NFS share, batch upload nightly.” It seems pragmatic until the first schema change or when 15 devices fall out of sync. The fragility shows up at scale.
Azure Synapse vs. AWS Redshift: Not a Symmetric Choice
Too often, Synapse and Redshift get treated as interchangeable “cloud warehouses.” They’re not. The differences matter when you design edge-to-cloud coordination.
- Synapse integrates deeply with Event Hubs, IoT Hub, and the broader Azure Data Lake Storage (ADLS) ecosystem. If your edge fleet is already Azure-tethered (think industrial IoT setups with OPC UA gateways feeding IoT Hub), Synapse becomes the natural sink.
- Redshift leans heavily on S3 as the staging backbone. The COPY command is robust, and now with Redshift Spectrum and federated queries, you can query data in S3 without ingesting it all. This flexibility matters when edge-generated data doesn’t neatly fit warehouse tables.
In practice:
- Manufacturers with existing Azure OT integrations often default to Synapse.
- Logistics firms that have already standardized on AWS (for ERP, fleet tracking, and ML pipelines) tend toward Redshift.
And sometimes, the choice isn’t about tech fit at all. Procurement contracts, enterprise licensing deals, or even which cloud the CIO has a golf buddy at the end will be decided.
Coordination is as Much Organizational as Technical
It’s tempting to imagine edge-to-cloud coordination as a technical pipeline problem. It isn’t, not entirely.
- Edge teams want autonomy: they’ll say, “We’ll push whatever event JSON we want; the cloud team can figure it out.”
- Cloud architects push back: “We need consistent schemas, metadata standards, and lineage.”
- Data scientists add a third voice: “Don’t downsample too aggressively at the edge; we lose model retraining fidelity.”
The coordination problem becomes one of governance. Without clear agreements on what’s processed locally, what’s enriched in transit, and what’s stored centrally, you end up with disjointed systems.
A practical example: a food processing plant used Jetson units to detect defects on conveyor belts. Edge devices flagged defects with bounding boxes. But corporate QA wanted pixel-level samples to audit labeling accuracy. The compromise? Jetsons sent cropped defect images (not full frames) upstream. Small enough to move quickly, rich enough for retraining.
Latency vs. Fidelity: You Can’t Optimize for Both
Every architecture has to make a call: do you prioritize real-time reaction or historical depth?
- Low-latency preference: Push aggregated insights fast. Example: “Machine #12 vibration exceeds tolerance—shut it down now.” You don’t care about storing every vibration tick.
- High-fidelity preference: Preserve granular data for later correlation. Example: post-mortem analysis after a turbine failure requires all the detailed vibration traces.
With Jetson + Synapse/Redshift, you often end up with a tiered approach:
- Edge retains raw buffers for short windows.
- Cloud warehouses hold structured summaries.
- Cold storage (ADLS, S3 Glacier) archives full fidelity for rare retrieval.
This layering is the unglamorous but necessary middle ground.
Security and Trust in Transit
There’s a subtle security wrinkle many miss. Edge-to-cloud often relies on intermittent connectivity. Devices may cache results locally and sync when bandwidth appears. But what if those devices are compromised during downtime? How do you ensure tamper-proof syncs?
Some field teams implement:
- Signed event logs, where Jetson appends HMAC signatures that cloud-side services validate before ingestion.
- Immutable object storage as the first cloud storage (S3 with object lock or ADLS immutable blobs) before warehouse loading.
- Hardware-backed secure enclaves on the Jetson, though these can be overkill unless you’re in regulated industries.
In regulated verticals (pharma, defense, finance), these extra steps aren’t optional—they’re audit requirements.
Lessons from Real Deployments
Two stories stand out.
1. Logistics company, fleet video monitoring
- Edge: Jetson devices in trucks ran driver fatigue detection.
- Cloud: AWS Redshift was the target, but direct ingestion was unmanageable.
- Solution: Jetsons sent compact fatigue event logs via MQTT → Kinesis → S3 → Redshift. Raw video never left the truck; only events and selected clips were synced during depot WiFi sessions.
- Outcome: Analysts could correlate fatigue events with shift schedules without drowning in raw video.
2. Factory automation, defect detection
- Edge: Jetson Orin devices classify product defects in real time.
- Cloud: Azure Synapse connected to Power BI dashboards.
- Pipeline: Jetson → IoT Hub → Stream Analytics → Synapse.
- Nuance: Models updated monthly, but schema drift (new defect categories) broke downstream reports. Eventually, they introduced schema versioning at Event Hub to keep dashboards stable.
Both cases show the same theme: the tech works, but only after governance catches up.
Where It Breaks Down
It’s worth acknowledging where this whole vision doesn’t hold.
- Rural deployments with weak connectivity: If trucks only see patchy LTE, “real-time” ingestion is a fantasy. Architect accordingly.
- Underfunded ops teams: Maintaining brokers, ETL jobs, and schema registries is overhead. Without proper ops, brittle pipelines collapse.
- Misaligned incentives: Edge engineers optimize for inference speed; analysts optimize for rich datasets. Unless leadership mediates, you’ll get siloed optimizations that don’t add up.
This isn’t a technology shortcoming as much as an organizational one.
The Way Forward
Edge-to-cloud isn’t about choosing Synapse or Redshift. It’s about creating a choreography where each layer does what it’s best at.
- Jetson handles raw mess and immediate decisions.
- Cloud warehouses handle structured analysis and integration with enterprise systems.
- Storage layers (ADLS, S3) act as the safety net for everything in between.
When organizations recognize that each role is distinct but complementary, pipelines stop being brittle “projects” and start becoming resilient systems.
The irony? The tech stack—Jetson, Synapse, Redshift—is evolving fast. But the principles aren’t new. It’s the same old struggle of distributed systems: what to compute locally, what to centralize, and how to keep humans aligned in between.