Key Takeaways
- Discovery is decisive. Picking the wrong process at the start can derail an entire automation program; stability often trumps sheer volume or pain points.
- Politics drive prioritization. Scoring models help, but early wins that prove credibility usually outweigh the most “objectively” valuable candidates.
- Design must reflect reality. Bots fail when they’re built for sanitized process maps instead of the messy, real-world workflows people actually follow.
- Automation isn’t fire-and-forget. Monitoring and optimization are essential—processes evolve, and unattended bots inevitably break.
- Programs need an end-of-life plan. Decommissioning outdated bots prevents hidden costs and compliance risks from creeping into the automation estate.
Anyone who has lived through an automation program knows it never runs the way the vendor slide deck suggested. On paper, it’s a straight arrow: spot inefficiency → build a bot → measure savings. In practice, it looks more like scaffolding around an old building—constantly patched, rerouted, and occasionally dismantled altogether. And yet, despite the messiness, there is a recognizable cycle. It’s not clean, but it is consistent.
This isn’t an academic overview. It’s the lifecycle as seen in real companies—banks, manufacturers, healthcare providers—where automation bumps up against legacy systems, middle managers, and human habits that refuse to die quietly.
Also read: How to Involve Department Heads in Automation Strategy Planning
Discovery: Hunting for Candidates
Discovery is the least glamorous but most decisive phase. It’s sitting with accounts payable clerks while they wrestle with supplier invoices. It’s realizing that the “five-step” claims workflow documented in SharePoint is actually 17 steps when done in practice.
Mistakes here echo all the way through the lifecycle. Chasing the wrong process is like pouring concrete on bad foundations. I’ve seen programs stall for months because teams picked their “biggest pain point” first. One finance function wanted month-end close automated—it looked like the perfect target. But when we mapped it, we found every quarter brought new exceptions, spreadsheet tweaks, and undocumented overrides. Trying to automate that was a fool’s errand. We shifted focus to invoice validation instead. Less prestige, more stability, and far more realistic.
A few truths from the discovery trenches:
- Big doesn’t mean good. High transaction counts look great in a business case, but if half require judgment calls, automation quickly collapses.
- Upstream chaos ruins downstream automation. Don’t automate order entry if the CRM keeps spitting out bad data.
- Pain doesn’t equal potential. The tasks people complain about most are often the hardest to stabilize for automation.
Discovery done well combines analytics with observation. Process mining highlights bottlenecks; watching real employees shows you the shortcuts, the Post-it notes, and the “oh, I just do this manually because the system freezes sometimes.” Ignore that human side, and you’ll design bots for a fantasy process.
Assessment and Prioritization
Every organization eventually builds some kind of scoring model—volume, error rate, FTE savings, compliance risk. Sounds scientific, doesn’t it? The reality: prioritization sessions are political. Finance will argue for cost savings. Compliance will push high-risk controls. Operations just wants relief from the drudgery.
And here’s the contradiction: the objectively most valuable process isn’t always the best first choice. Early on, you need a quick win more than a monster ROI. Something that goes live in six weeks and proves the concept often buys more credibility than a complex automation that drags on for months.
It’s worth remembering that automation programs live or die not on technical grounds, but on perception. A CFO who sees a bot reconciling invoices every morning is more likely to fund the next wave.
Design: Reconciling Theory with Reality
Design is where requirements turn into architecture. This is the stage that reveals just how tidy—or untidy—process documentation really is.
At one hospital group, claims processing was “a ten-step procedure.” In reality, agents made dozens of micro-decisions that had never been written down. Automating it meant designing for that chaos, not for the sanitized version on paper.
Strong design work doesn’t just capture the happy path. It:
- Documents exceptions honestly (even the ugly ones).
- Plans for failure—logging, alerts, retry logic.
- Considers the human handoffs. Bots don’t operate in a vacuum.
- Avoids gold-plating. Sometimes the fastest answer is a small script, not a multi-system API integration.
And design is also where governance needs to enter the room. Data access, audit trails, and credential management—if those aren’t built in, you’ll end up retrofitting controls later, usually under audit pressure.
Development: Building Under Real-World Constraints
Executives often assume that once design is done, the hard work is over. Developers just “drag and drop” workflows, right? If only.
The reality of bot building:
- Systems aren’t stable. An ERP screen moves a button two pixels, and your carefully scripted click breaks.
- Credential rules choke progress. Security balks at service accounts, but bots can’t run without them.
- Version drift kills you. The bot was tested on Office 2019; production runs Office 365 with different dialog boxes.
The most seasoned developers treat bots like serious software—structured code, reusable components, and proper error handling. If you treat them like macros, you end up firefighting every week.
Testing: Where Assumptions Go to Die
Testing is the graveyard of rosy assumptions. Bots that ran perfectly in a dev sandbox suddenly fail when exposed to real data volumes or quirky scenarios.
Failures caused by:
- Date fields flip formats depending on user settings.
- Quarterly pop-ups are only triggered by a subset of vendors.
- Banner messages shifting a button slightly lower, confusing the bot.
Good testing is not “run it ten times and see if it works.” It’s deliberately trying to break the bot. Run it under load, run it during system maintenance windows, and throw bad data at it. That’s the only way to avoid support tickets piling up after go-live
Deployment: Not the Finish Line
Deployment is often celebrated as the end of the project, but it’s really just the start of operational ownership. A successful go-live requires:
- Scheduling so bots don’t compete with humans for system access.
- Monitoring dashboards that show not just success/fail, but why.
- Support staff trained on exception handling.
- A rollback plan—because first runs rarely go without hiccups.
And don’t underestimate perception. If staff don’t trust the bot, they’ll double-check its output, negating the efficiency. Showing people logs, error rates, and escalation paths builds that trust.
Monitoring and Ongoing Tuning
A bot left alone is a bot that breaks. Business processes aren’t static—policies shift, systems upgrade, and vendors change formats. Without monitoring, you’re blind to creeping degradation.
The best-run programs track metrics like
- Throughput (is volume staying consistent?)
- Exception rates (are more cases getting kicked out over time?)
- Error logs (do they show patterns that hint at underlying process drift?)
Sometimes monitoring reveals that the process itself is the problem. One manufacturer automated vendor onboarding, only to realize half the fields collected duplicate data. They simplified the workflow, which ironically made parts of the bot redundant. That’s success, though it doesn’t look like it on the balance sheet.
Scaling the Program
One bot is proof of concept. Ten bots is a portfolio headache. Scaling means building infrastructure for repeatability
- A governance model that defines who owns what.
- Reusable components—authentication modules, logging frameworks.
- A central catalog of automations, so people know what exists and avoid rebuilding.
This is where organizations either mature or stagnate. Without structure, you end up with dozens of tactical bots, fragile and siloed. With discipline, you create an ecosystem where automations reinforce each other.
The Forgotten Phase
Nobody likes to talk about decommissioning. But bots outlive their usefulness just like applications do. Systems consolidate, policies shift, or compliance rules change. Leave old bots running and you’ll eventually get bitten by zombie automations that fail silently.
A clean decommission involves archiving logs, revoking credentials, and notifying business owners. Boring? Absolutely. Necessary? Without question.
Hard-Won Lessons
Across industries, a few lessons come back again and again:
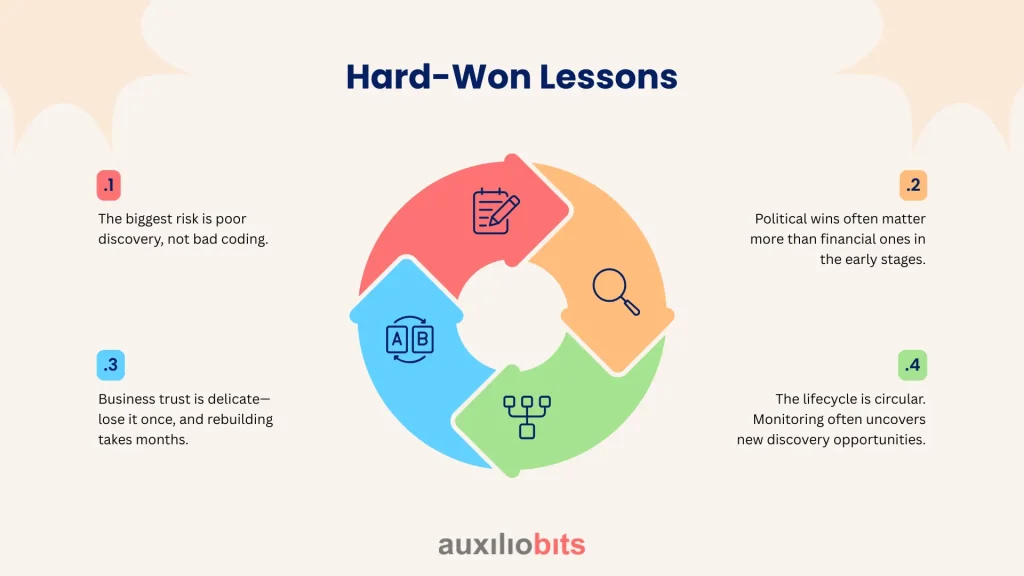
- The biggest risk is poor discovery, not bad coding.
- Political wins often matter more than financial ones in the early stages.
- Business trust is delicate—lose it once, and rebuilding takes months.
- The lifecycle is circular. Monitoring often uncovers new discovery opportunities.
And the hardest truth: automation doesn’t remove people; it changes their work. The best programs don’t just chase headcount reduction; they free employees from drudgery so they can handle exceptions, improve processes, or simply move faster.
Final Word
The automation lifecycle—discovery, prioritization, design, build, testing, deployment, monitoring, scaling, and eventually decommissioning—isn’t neat. Each stage has its own traps and trade-offs. But seeing it honestly, not as a vendor slide but as a living cycle, helps leaders make smarter bets.
Automation isn’t static. Processes evolve, systems upgrade, and people adapt. If your automation program can evolve with them, it stands a chance of lasting.