
Key takeways
- RPA can automate everything, from legacy applications to modern complex applications, that a human can do with her hands.
- Artificial Intelligence works with RPA to overcome its shortcomings and elevates traditional RPA to the next level.
- Today businesses are leveraging the collaborative power of RPA and AI to achieve complete digital transformation.
- Documents come in many forms and shapes. Files may contain structured, semi-structured, and unstructured data. These variations make it difficult to understand documents.
- RPA provides a way to process documents using the inherent AI capabilities that are an integral part of modern-day automation software.
- Today’s RPA tools are equipped with built-in AI and ML capabilities to help them understand documents, extract information, and interpret according to the enterprise business process automation requirements.
Robotic Process Automation started as a technology proving its value in automating rules-based and repetitive tasks throughout an enterprise. From legacy applications to modern complex applications RPA can automate everything that a human can do with her hands. However with the advent of technology we have come to know that traditional RPA cannot tackle a significant amount of work that may need decision making or cognitive capabilities such as predicting sales or classifying emails. Here is when Artificial Intelligence comes into play and helps traditional RPA to have new wings to be at the next level.
Consider traditional RPA as a human hand and AI as the brain. The brain and hands can achieve little when working in isolation but when working in tandem they can achieve the unthinkable and human evolution is an example of that. Today RPA software providers have come up with their respective AI offerings to leverage the benefits of this collaboration and achieve a complete digital transformation… And this can be leveraged to have an intelligently automated enterprise.
Need For Document Understanding
Consider how much time employees in an enterprise spend on document processing. And it gets even more challenging when the documents vary in structure.Some of them have a fixed format and are easy to read and process, like forms, passports and licenses. Some of the documents have no fixed structure at all like contracts, emails and health records. Some of the documents can be a mix of fixed and variable data like invoices, purchase orders and utility bills. This is the reason automating processes that involve these structured, semi-structured and unstructured documents has been very difficult even with traditional automation software.
How RPA helps in understanding documents
RPA provides a way to process documents using the inherent AI capabilities that are an integral part of the modern day automation software. RPA provides a way to process documents intelligently with the help of AI. To learn how to process all the documents coming their way the RPA robots learn how to read and interpret documents. The robots review rules and expressions and memorize the names of the fields that need to be read and interpreted from a type of document. The robots are trained using Machine Learning to enable them to be smart to know how to approach a specific document, be it a passport, receipt, invoice or utility bill. With the help of Machine Learning the robots become aware about varying templates of documents received, handwriting understanding, signatures, check-boxes, skewed or rotated documents, various file formats and low quality scanned documents.
The human in the loop (HIL) feature allows the humans to validate the data read by the robots of which the robots are unsure. When the HIL validation happens that acts as a feedback loop to the machine learning model of the RPA robot to learn and handle that situation next time it encounters such data. This framework of having RPA robots use ML and HIL results in rapid and accurate results thus saving a lot of costs, thus mitigating the risk to avoid human error and related losses and improve customer experience. This obviously saves employees from mundane daily tasks and makes them happier and more productive by helping them focus on higher value tasks.
Document Structures
As you may have got it by now document understanding is the intelligent ability to extract and interpret information and meaning from a wide range of document types, storage formats and objects. Document structure can be classified into three main categories:
- Structured Documents: Structured documents are focused on collecting information in a precise almost fixed format, guiding the person who is filling the document with precise areas where each piece of information needs to be entered. These come in a fixed format and are called forms. Examples of structured documents include Surveys, Questionnaires, Tax Forms etc. These contain exclusively key/value pairs and tables
- Semi-Structured Documents: Semi structured documents are documents that do not follow a strict precise format as forms do and are not bound to a fixed format or data fields. Although these types of documents do not have a fixed format, they follow a common enough structure. These may contain paragraphs as well but the data extracted can be in the form of key-value pairs. Examples of semi-structured documents are invoices, receipts, purchase orders, healthcare lab reports, healthcare insurance claim reports etc.
- Unstructured Documents: Unstructured documents are documents in which the information isn’t organized according to a clear structured model. These files are all easily comprehensible by human beings, yet much more difficult for a robot. Examples of unstructured documents are contracts, annual reports. Some may contain key-value pairs and tables but most of the data is in unstructured form inside the textual descriptions.
Documents come in many forms and shapes and are usually one of the three categories above. There is also a possibility that a file can have various parts that are structured, semi structured and unstructured and these can be based on contexts.
Based on this classification there are majorly two ways of extracting data from documents.
- Rule-Based Data Extraction: Here the robots use a set of rules to extract data from a document. For instance document templates can be created and rules can be applied on specific data positions in the document to extract specific information. If the data needs to be extracted without defining templates, simple rules can be applied on how frequently some data sets are used in a document (occurrence patterns) or how data variables form a pattern (regular expressions or regex).
- Model-Based Data Extraction: Model based data extraction methods are based on machine learning models. This method extracts data from semi-structured document formats based on initial training data. And the ML model can be retrained based on the feedback-loop. From an unstructured document this method needs to read the text from the document to extract the meaning and identify the right data. Similar to semi-structured document understanding the ML model needs to be pre-trained on datasets and can be retrained based on HIL or other varied document data.
As a matter of fact all these methodologies can be used in a hybrid approach to fit the need of document understanding and the context.
Is OCR the same as Document Understanding?
Document understanding is a concept that involves various concepts to follow a series of steps to extract and interpret information. Optical Character Recognition (OCR) is a method of reading text from images, recognizing each character and its position in the document. OCR is used to digitize the documents that may not have native format like the scanned images. Document Understanding involves in principal 5 fundamental steps: defining document types and data to be extracted (Taxonomy), providing text and its location (OCR), classifying documents from the specified list (Classify), extracting the information (Extract) and confirming the extracted data by a human (HIL or Validate). Hence OCR is a method that helps in the digitization step of the document understanding process.

How AI helps in Document Understanding - An Overview
Artificial Intelligence Terminology
To get us in the context let’s quickly look at what various AI terms mean
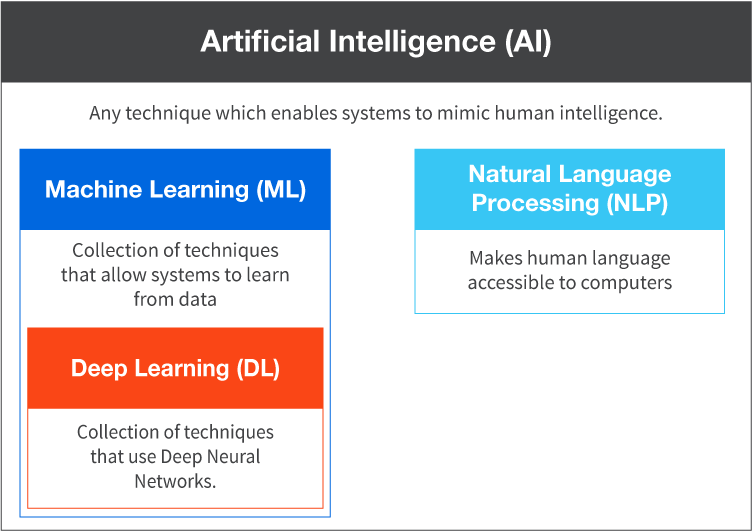
- Artificial intelligence (AI): An intelligence of the machine that is artificially built over a period of time and with incremental learning. This intelligence is similar to the human intelligence that would normally need decision making.
- Machine learning (ML): This is a subset of AI that utilizes algorithms to enable systems to learn from data generated through experience and systems that generate historical data. These systems are self learning without being needed to be explicitly programmed.
- Deep Learning (DL): This is an area of Machine Learning that is concerned with artificial neural networks. DL is a series of algorithms that aim to recognize a set of data through a process that mimics biological neural networks.
- Natural Language Processing (NLP): NLP is a branch of Artificial Intelligence that can help in analyzing, understanding and generating the human natural languages and documents. For instance NLP helps applications and systems to read and understand text from emails, documents (PDF etc), speech and also understand the sentiments as one scenario.
A little insight into Machine Learning
The best way to understand machine learning is that we can consider it as a function that maps input to an output. We can consider machine learning as a target function that based on the previous learning can map an input to a desirable output without the need of retraining it in most of the cases. Consider the following image

Knowing how machine learning works!
Machine learning literally means machines trying to learn through experience. This is similar to a new born child learning from the environment that feeds data in her brain to automatically learn and relearn. This is called experiential learning and in case of ML it is through data that is fed to the algorithm. The software program solves a problem or predicts something by making a prediction based on the input data, which is often labelled or cleaned up to be fed to the machine learning algorithm.
The machine learning incremental learning has the following components
- Data: Data or Datasets is the most important prerequisite for an ML model to make a prediction and get trained. Training datasets are fed to the ML algorithm to facilitate incremental learning.
- Model (For Analysis): The set of data and observations allow us to fit a function to the ML model. Once a model is created to analyze the training data we are ready to make predictions.
- Prediction: The input data will be applied to the function and a prediction is made to get the desired output.
- Feedback Loop: The juice of machine learning lies in its ability to learn and relearn from the feedback. This feedback can be provided by a human or through other means and the machine learning function is enhanced to learn to act on such dataset.
Types of Machine Learning
Depending on the way a machine learning model is trained using datasets machine learning can be classified into:
- Supervised Learning: Here the ML model maps the input to the desired output. The training goes on until there is an acceptable level of accuracy in predicting the outcome after which the learning stops. Supervised learning can solve the problem of classification (to predict write or wrong, spam or no spam, red or blue etc) and Regression (that is outputting a real value like weight, number etc).
- Unsupervised Learning: We only have input datasets here and no defined outputs. This type of algorithm models the underlying structure of the data with no correct prediction or answers and no retraining scope. This type of machine learning solves two problems namely Clustering (inherent grouping of the data or categorizing the type of credit card transactions for example) and Association (defining data correlation like if X category of people buy A they will also buy B)
- Reinforcement Learning: Algorithms here solve an uncertain problem in a complex environment only by trial and error through the method of rewards and punishments. There is no correct answer but the feedback is given in the form of rewards and penalties. For instance if a robot is trying to hit a soccer goal. Every time the robot hits the goal it knows it has achieved something correct and remembers that learning of putting the ball in the goal.
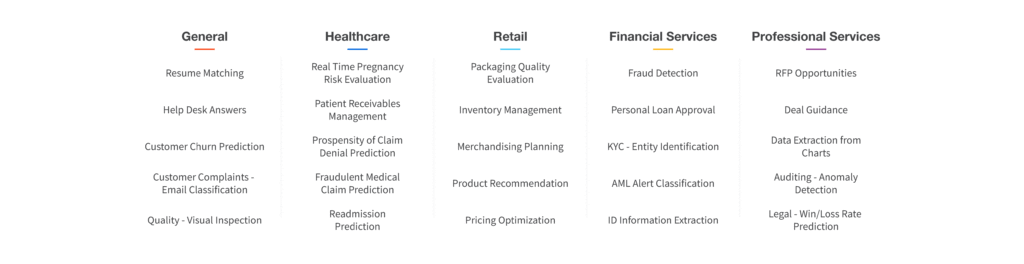
Where Machine Learning is being used
Machine learning is being used in various fields from general use, Healthcare, financial services to retail. A few of these can be seen in the following image.
Machine learning for Document Understanding
As per the steps mentioned in this article ML is used to help RPA understand documents. Out of the 5 major steps machine learning is used in Classification and Extraction through applying pretrained models and having them retrain using the feedback loops in the process. The feedback loops are either facilitated by the human in the loop (HIL) feature or some king of manual validation.
Document Understanding through ML provides RPA an edge over traditional automation tools and results in:
- Direct Cost Savings: If automated processing documents can result in dramatic cost savings, cutting costs to process huge amounts of data.
- Higher Straight Through Processing (STP): As documents are read and interpreted for actionable processes there is a reduced need for manual knowledge to be able to process documents.
- Secure and Reliable document handling: As the RPA robots get retrained based on the feedback loops they become reliable over a period of time. And the enterprise security levels make them more secure than what a human intervention would be.
- Accuracy enhancement: Processing a high volume of documents through a set of machine learning models and embedded rules the accuracy of processing documents is enhanced manifolds.
- Process Efficiency: Document processing enables end to end automation of large document-centric enterprise processes.
Today’s RPA tools are equipped with built in AI and machine learning capabilities to help them understand documents that allow them to extract information and interpret according to the enterprise business process automation requirements. Document understanding may be used in areas where there is uncertainty (where we cannot determine the outcome with 100% accuracy), high variability (where the rule based automation won’t work due to high variation in the structure of the documents) and unstructured data (where information is present in emails, images, articles etc.). The use cases of utilizing document understanding range from property valuations, loan defaults, inventory forecasts, resume matching, purchase decisions, invoice extraction, email routing to language translation.




